usethis::use_course("https://www.dropbox.com/sh/4kfzosb8r7nphsz/AACVc6ddvnWIa3WOUcLhJfrqa?dl=1")Web Scraping
A relatively new form of data collection is to scrape data of the internet. This involves simply directing R or Python to a specific web site (technically, a URL) and then collect certain elements of one or more pages on the target web site. A web page consists of HTML elements (or “nodes”) and as long as you know which element you want to grab, it is relatively straightforward for Python and R to do so.
You can download the code and data for this module by using this dropbox link: https://www.dropbox.com/sh/4kfzosb8r7nphsz/AACVc6ddvnWIa3WOUcLhJfrqa?dl=0. If you are using Rstudio you can do this from within Rstudio:
The key libraries to familiarize yourself with if you are interested in web scraping is BeautifulSoup for Python and rvest for R. Let’s start with a very simple example: Scraping a table from a page on Wikipedia
Scraping a Wikipedia Table
We will generally use the BeautifulSoup library for scraping in Python, but if you have a very simple scraping task, you can sometimes get it done by simply using the read_html function in pandas. Since polars do not have an alternative to ‘read_html’ as of now what we can do is read the data using pandas and then covert it to pandas for processing. This function scans a web page for html tables and then returns the tables into a list of pandas dataframes.
Suppose we want a dataframe of the latest population counts for each official country. A table with the relevant data exists on this Wikipedia page. This is a small and simple scraping example in that what we are really only interested in one table on web page. Since we only need an html table we can just use read_html in pandas:
import polars as pl
import pandas as pd
URL = 'https://en.wikipedia.org/wiki/List_of_countries_and_dependencies_by_population'
df_list = pd.read_html(URL) # this parses all the tables in to a list
df = df_list[1] # we seek the first table
polars_df = pl.from_pandas(df)
print(polars_df.head())shape: (5, 2)
┌───────────────────────────────────┬───────────────────────────────────┐
│ .mw-parser-output .navbar{displa… ┆ .mw-parser-output .navbar{displa… │
│ --- ┆ --- │
│ str ┆ str │
╞═══════════════════════════════════╪═══════════════════════════════════╡
│ Global ┆ Current population United Nation… │
│ Continents/subregions ┆ Africa Antarctica Asia Europe No… │
│ Intercontinental ┆ Americas Arab world Commonwealth… │
│ Cities/urban areas ┆ World cities National capitals M… │
│ Past and future ┆ Past and future population World… │
└───────────────────────────────────┴───────────────────────────────────┘We will generally use the BeautifulSoup library for scraping in Python, but if you have a very simple scraping task, you can sometimes get it done by simply using the read_html function in pandas. This function scans a web page for html tables and then returns the tables into a list of pandas dataframes.
Suppose we want a dataframe of the latest population counts for each official country. A table with the relevant data exists on this Wikipedia page. This is a small and simple scraping example in that what we are really only interested in one table on web page. Since we only need an html table we can just use read_html in pandas:
import pandas as pd
URL = 'https://en.wikipedia.org/wiki/List_of_countries_and_dependencies_by_population'
df_list = pd.read_html(URL) # this parses all the tables in to a list
df = df_list[1] # we seek the first table
print(df.head()) .mw-parser-output .navbar{display:inline;font-size:88%;font-weight:normal}.mw-parser-output .navbar-collapse{float:left;text-align:left}.mw-parser-output .navbar-boxtext{word-spacing:0}.mw-parser-output .navbar ul{display:inline-block;white-space:nowrap;line-height:inherit}.mw-parser-output .navbar-brackets::before{margin-right:-0.125em;content:"[ "}.mw-parser-output .navbar-brackets::after{margin-left:-0.125em;content:" ]"}.mw-parser-output .navbar li{word-spacing:-0.125em}.mw-parser-output .navbar a>span,.mw-parser-output .navbar a>abbr{text-decoration:inherit}.mw-parser-output .navbar-mini abbr{font-variant:small-caps;border-bottom:none;text-decoration:none;cursor:inherit}.mw-parser-output .navbar-ct-full{font-size:114%;margin:0 7em}.mw-parser-output .navbar-ct-mini{font-size:114%;margin:0 4em}vteLists of countries by population statistics .mw-parser-output .navbar{display:inline;font-size:88%;font-weight:normal}.mw-parser-output .navbar-collapse{float:left;text-align:left}.mw-parser-output .navbar-boxtext{word-spacing:0}.mw-parser-output .navbar ul{display:inline-block;white-space:nowrap;line-height:inherit}.mw-parser-output .navbar-brackets::before{margin-right:-0.125em;content:"[ "}.mw-parser-output .navbar-brackets::after{margin-left:-0.125em;content:" ]"}.mw-parser-output .navbar li{word-spacing:-0.125em}.mw-parser-output .navbar a>span,.mw-parser-output .navbar a>abbr{text-decoration:inherit}.mw-parser-output .navbar-mini abbr{font-variant:small-caps;border-bottom:none;text-decoration:none;cursor:inherit}.mw-parser-output .navbar-ct-full{font-size:114%;margin:0 7em}.mw-parser-output .navbar-ct-mini{font-size:114%;margin:0 4em}vteLists of countries by population statistics.1
0 Global Current population United Nations Demographics...
1 Continents/subregions Africa Antarctica Asia Europe North America Ca...
2 Intercontinental Americas Arab world Commonwealth of Nations Eu...
3 Cities/urban areas World cities National capitals Megacities Mega...
4 Past and future Past and future population World population es... The most popular package for web scraping in R is rvest. The only challenge in using this package (and any other scraper package) is finding the name/identity of the part of the web page you are interested in.
Scraping with rvest starts out by you telling R what web page (URL) you want to scrape (parts of). R will then read the web page (so you have to be online for this to work) and you can then tell R which specific elements of the page you want to retain
Suppose we want a dataframe of the latest population counts for each official country. A table with the relevant data exists on this Wikipedia page. This is a small but pretty scraping example in that what we are really interested in (the table of population counts) is a part of a bigger web page.
We start by having R read in the relevant web page using the read_html function in rvest:
library(rvest)
library(tidyverse)-- Attaching core tidyverse packages ------------------------ tidyverse 2.0.0 --
v dplyr 1.1.1.9000 v readr 2.0.2
v forcats 1.0.0 v stringr 1.5.0
v ggplot2 3.4.2 v tibble 3.2.1
v lubridate 1.8.0 v tidyr 1.1.4
v purrr 0.3.4
-- Conflicts ------------------------------------------ tidyverse_conflicts() --
x dplyr::filter() masks stats::filter()
x readr::guess_encoding() masks rvest::guess_encoding()
x dplyr::lag() masks stats::lag()
i Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsthePage <- read_html('https://en.wikipedia.org/wiki/List_of_countries_and_dependencies_by_population')Ok - so far so good. Now comes the hard part: What is the name of the table we are interested in? We can clearly see it on the Wikipedia page - but what is that table’s name in the underlying html code? There are multiple ways to get at this. First, of all we can simply query the scraped page using the html_nodes function in order to list all nodes that are tables:
html_nodes(thePage,"table"){xml_nodeset (3)}
[1] <table class="wikitable sortable" style="text-align:right"><tbody>\n<tr c ...
[2] <table class="nowraplinks hlist mw-collapsible autocollapse navbox-inner" ...
[3] <table class="nowraplinks mw-collapsible autocollapse navbox-inner" style ...This is a little bit of a mess, but if you inspect the output of the first table (“wikitable”) in the R console, you will see that this is the table we want. A more elegant approach is to look at the actual html code underlying the web page. In Google’s Chrome browser you can hit Fn+F12 to get to the browser’s Developer Tools. You can then click on the Elements browser (the little square with a cursor in it) and then hover over different parts of the web page to see the relevant part of the html code. The image below shows that the population table is a “wikitable” class. You can also use a browser plug-in for the same functionality. A popular Chrome exentionsion for this purpose is selectorgadget.
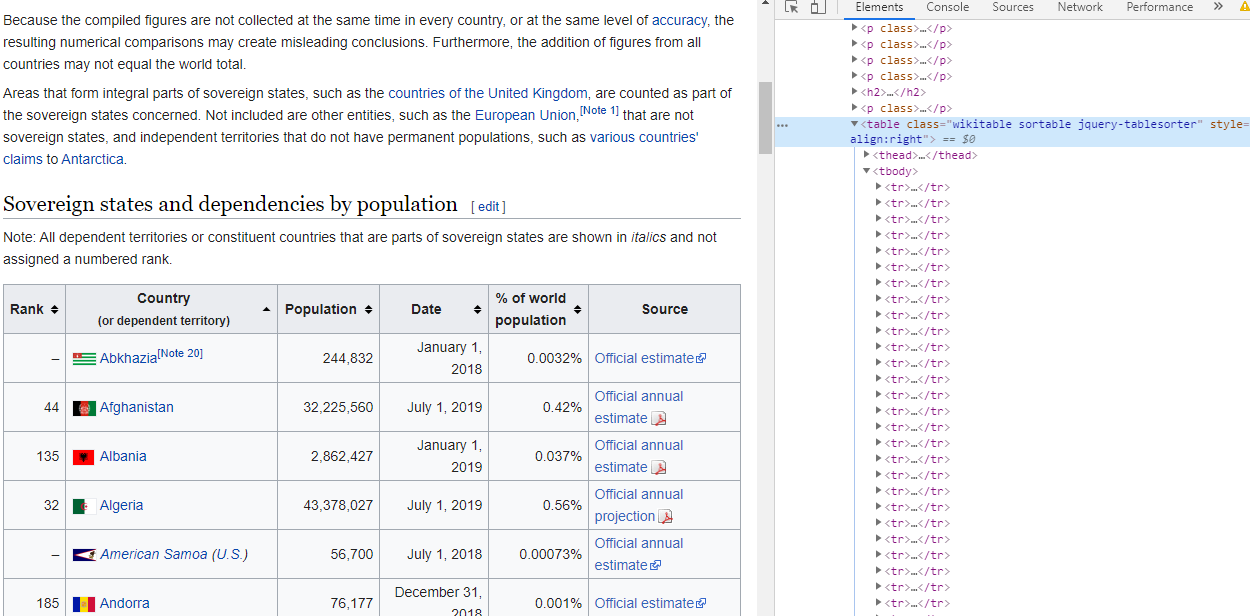
Having now identified the name/class of what we need we can pick that element out of the web page (here using pipe syntax):
WorldPoP <- thePage %>%
html_node(".wikitable") %>%
html_table(fill = TRUE)First we grab the relevant table (note that you need to add a “.” in front of the class name - or you could write (“table.wikitable”)). The last function html_table turns the html table into an R data frame (with NAs added where values are missing):
glimpse(WorldPoP)Rows: 242
Columns: 7
$ `` <chr> "–", "1", "2", "3", "4",~
$ `Country / Dependency` <chr> "World", "China", "India~
$ Population <chr> "8,062,382,000", "1,411,~
$ `% ofworld` <chr> "100%", "17.5%", "17.3%"~
$ Date <chr> "27 Sep 2023", "31 Dec 2~
$ `Source (official or fromthe United Nations)` <chr> "UN projection[3]", "Off~
$ `` <chr> "", "[b]", "[c]", "[d]",~Scraping user reviews from WebMD
 Let us now try a more ambitious scraping project: Scraping a large number of online user reviews. We will scrape reviews from prescription drug users from the website WebMD. This is a general health web site with articles, blog posts and other information with the goal of managing users’ health. One of the features of the web site is to host online reviews of a large number of precription drugs.
Let us now try a more ambitious scraping project: Scraping a large number of online user reviews. We will scrape reviews from prescription drug users from the website WebMD. This is a general health web site with articles, blog posts and other information with the goal of managing users’ health. One of the features of the web site is to host online reviews of a large number of precription drugs.
Suppose we want to scrape user reviews for the drug Abilify. This is a drug prescribed to treat various mental health and mood disorders (e.g., bipolar disorder and schizophrenia). We start by navigating to the review page which is here. Here we make a number of observations. First of all, not all reviews are listed on one page - they are distributed across a large number of pages with only 20 reviews per page. Second of all, a user review consists of multiple components: A 5 point rating for each of three measures, a text review (called “comment”), the date of the review, the condition of the reviewer and some demographics (gender and age).
In order to get going on this scraping project, we use the following sequential strategy:
1.First figure out how to scrape one page of reviews and write your own function that performs this action. 2.Find out how many pages of reviews there are in total and what the naming convention is of each page. 3.Run the function defined in 1. on each page in 2. and bind all reviews together into one large dataframe.
More involved scraping tasks like the one above can be accomplished using the beautifulsoup module in Python. When scraping with beautifulSoup you will often need to pretend to be a browser - otherwise the website might not allow you access. First we set up a browser and set the main URL of the web page:
import polars as pl
import requests
from bs4 import BeautifulSoup
headers = requests.utils.default_headers()
headers.update({
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0',
})
base_url = 'https://www.webmd.com/drugs/drugreview-64439-abilify'Next we access the webpage (using the get function) and then use BeautifulSoup to read all the elements of the page:
page = requests.get(base_url, headers=headers)
soup = BeautifulSoup(page.content,"lxml")The content of the web page is now contained in the object soup. At this point we need to figure out which elements we want from the full page. Using Chrome Developer Tools or Selectorgadget, we find that that each user review (including user characteristics) is contained in “div” tag with a class called “review-details”.
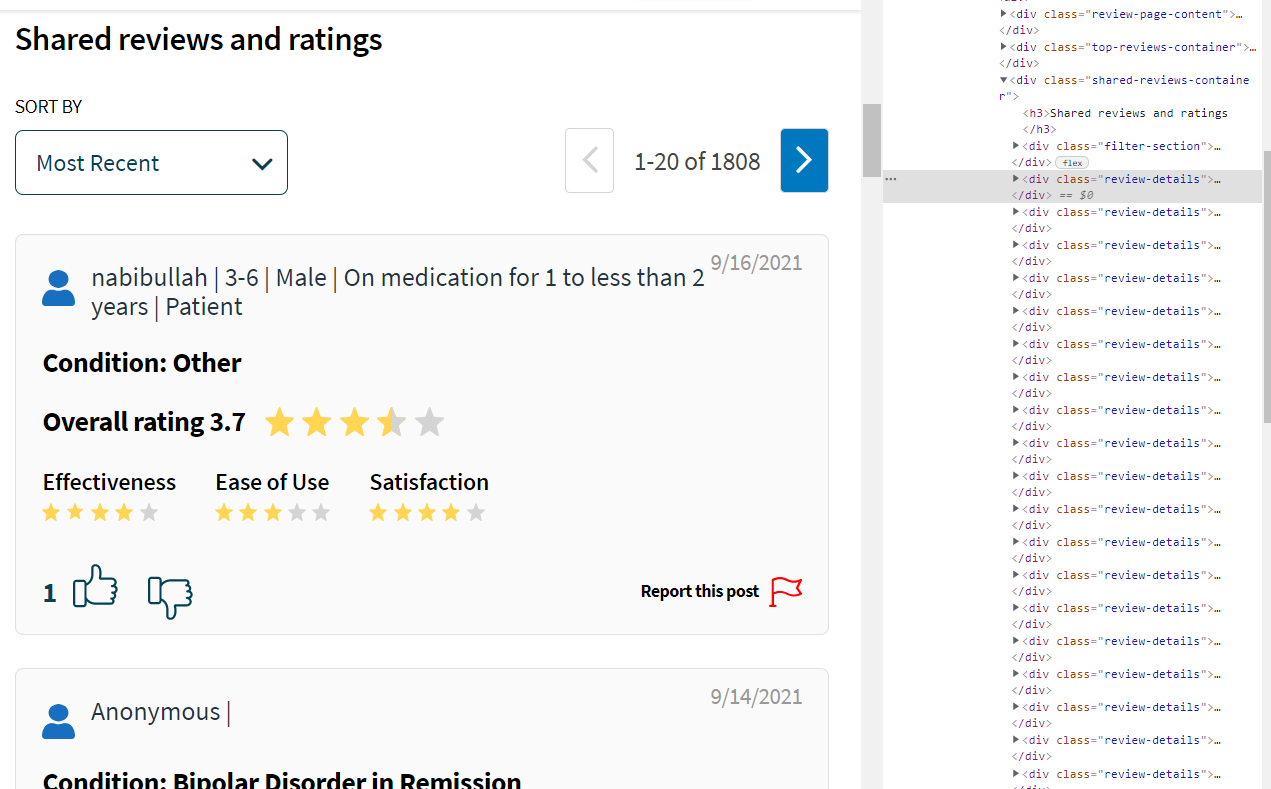
We start by grabbing all of the “review-details” elements using find_all:
each_review = soup.find_all("div",{"class": "review-details"})Ok - now we have the information we need. Now it’s just a matter of finding out what all the sub-elements of each review are called. Suppose we were only interested in the information about each reviewer. This is contained in another div tag with class “details”. If we want the details for all reviewers on the first page, we can just cycle through each review contained in each_review and pick out the “details” element from each review. There are different ways of doing this. Here we will do it by collecting the individual elements in a list by stripping out the text of each of the “details” elements:
info = []
# cycle through all reviews
for theReview in each_review:
# reviewer info
row = theReview.find("div", {"class": "details"}).text.strip()
info.append(row)
print(row)
#print(info)Gabe | 19-24 | Male | On medication for less than 1 month | Patient
Anonymous | 25-34 | Male | On medication for 5 to less than 10 years | Patient
Say no to abili | 35-44 | Male | On medication for 5 to less than 10 years | Patient
SamRS | 45-54 | Female | On medication for 6 months to less than 1 year | Patient
Anonymous | 55-64 | Male | Patient
Alex Adams | 25-34 | Male | On medication for 1 to 6 months | Patient
Roxanne | 65-74 | Transgender | On medication for 2 to less than 5 years | Patient
Roses | 19-24 | Male | On medication for 6 months to less than 1 year | Caregiver
Sara | 25-34 | Female | On medication for less than 1 month | Patient
Kitty | 19-24 | Female | On medication for 2 to less than 5 years | Patient
Scaredmommabear | 7-12 | Male | On medication for less than 1 month | Caregiver
SB09 | Patient
Anonymous | 45-54 | Female | On medication for 2 to less than 5 years | Patient
Anonymous | 13-18 | Transgender | On medication for 1 to 6 months | Patient
DJ | 19-24 | Male | On medication for 1 to 6 months | Patient
Lana | 19-24 | Female | On medication for 1 to less than 2 years | Patient
Elizabeth Gutierrez | 25-34 | Female | On medication for 2 to less than 5 years | Patient
Rhen | 75 or over | Female | On medication for less than 1 month | Patient
Barbara | 65-74 | Female | On medication for 2 to less than 5 years | Patient
Matt | 35-44 | Male | On medication for 1 to 6 months | PatientNow we can just add additional elements to this. For example, we will also want the underlying medical condition for each reviewer. This element is a little more tricky since it has missings - some reviewers don’t list their underlying condition. This is actually not a problem on the first page but it will be on subsequent pages. So we need to flag the missings whenever they exist. We do this by adding an if statement so that the text of the “condition” class is only collected when it exists:
condition = []
info = []
# cycle through all reviews
for theReview in each_review:
# reviewer info
row = theReview.find("div", {"class": "details"}).text.strip()
info.append(row)
# condition
row = theReview.find("strong", {"class": "condition"})
theCondition = "NA"
if row:
theCondition = row.text.strip()
condition.append(theCondition)
print(theCondition)
#print(condition)Condition: Other
Condition: Other
Condition: Bipolar I Disorder with Most Recent Episode Mixed
Condition: Mania associated with Bipolar Disorder
Condition: Additional Medications to Treat Depression
Condition: Schizophrenia
Condition: Additional Medications to Treat Depression
Condition: Other
Condition: Manic-Depression
Condition: Other
Condition: Other
Condition: Other
Condition: Additional Medications to Treat Depression
Condition: Other
Condition: Schizophrenia
Condition: Additional Medications to Treat Depression
Condition: Bipolar I Disorder with Most Recent Episode Mixed
Condition: Additional Medications to Treat Depression
Condition: Bipolar Disorder in Remission
Condition: SchizophreniaOk - loooks good. We are going to add a few more elements that we want to retain and the put the whole thing into a function:
def scrapeThePage(theSoup):
"""This function scrapes one page from WebMD"""
# first grab all reviews on page
each_review = theSoup.find_all("div",{"class": "review-details"})
# initialize lists
condition = []
info = []
comment = []
rating = []
# cycle through reviews
for theReview in each_review:
# condition (making sure to flag missings)
row = theReview.find("strong", {"class": "condition"})
theCondition = "NA"
if row:
theCondition = row.text.strip()
condition.append(theCondition)
# reviewer info
row = theReview.find("div", {"class": "details"}).text.strip()
info.append(row)
# text comment (making sure to flag missings)
row = theReview.find("p",{"class": "description-text"})
theComment = "NA"
if row:
theComment = row.text.strip()
comment.append(theComment)
# rating
row = theReview.find("div",{"class": "overall-rating"}).text.strip()
rating.append(row)
return condition, info, comment, ratingThis function returns four lists containing information for each review. Now we can just call this function for each of all the review pages for the drug we are interested in.
In order to use the function above, we need find the URL for each review page. You can easily figure this out by advancing through the pages on WebMD. The pages are as follows:
https://reviews.webmd.com/drugs/drugreview-64439-abilify-oral?conditionid=&sortval=1&pagenumber=1
https://reviews.webmd.com/drugs/drugreview-64439-abilify-oral?conditionid=&sortval=1&pagenumber=2
https://reviews.webmd.com/drugs/drugreview-64439-abilify-oral?conditionid=&sortval=1&pagenumber=3
and so on up to the last page (page 91). We can recreate this in Python as
num_pages = 92
urls = ['{}?conditionid=&sortval=1&pagenumber={}'.format(base_url, pagenumber) for pagenumber in range(1,num_pages)]All we need to do now is just cycle through all the pages:
num_pages = 92
urls = ['{}?conditionid=&sortval=1&pagenumber={}'.format(base_url, pagenumber) for pagenumber in range(1,num_pages)]
allCondition = []
allInfo = []
allComment = []
allRating = []
for url in urls:
print(url)
page = requests.get(url, headers=headers)
soup = BeautifulSoup(page.content,"lxml")
l1, l2, l3, l4 = scrapeThePage(soup)
allCondition.extend(l1)
allInfo.extend(l2)
allComment.extend(l3)
allRating.extend(l4)
# collect results into dataframe
dict = {'Condition': allCondition, 'Reviewer': allInfo, 'Review': allComment, 'Rating': allRating}
allDataDF = pl.from_dict(dict)The final dataframe has 1,808 rows - one for each review.
More involved scraping tasks like the one above can be accomplished using the beautifulsoup module in Python. When scraping with beautifulSoup you will often need to pretend to be a browser - otherwise the website might not allow you access. First we set up a browser and set the main URL of the web page:
import pandas as pd
import requests
from bs4 import BeautifulSoup
headers = requests.utils.default_headers()
headers.update({
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0',
})
base_url = 'https://www.webmd.com/drugs/drugreview-64439-abilify'Next we access the webpage (using the get function) and then use BeautifulSoup to read all the elements of the page:
page = requests.get(base_url, headers=headers)
soup = BeautifulSoup(page.content,"lxml")The content of the web page is now contained in the object soup. At this point we need to figure out which elements we want from the full page. Using Chrome Developer Tools or Selectorgadget, we find that that each user review (including user characteristics) is contained in “div” tag with a class called “review-details”.
We start by grabbing all of the “review-details” elements using find_all:
each_review = soup.find_all("div",{"class": "review-details"})Ok - now we have the information we need. Now it’s just a matter of finding out what all the sub-elements of each review are called. Suppose we were only interested in the information about each reviewer. This is contained in another div tag with class “details”. If we want the details for all reviewers on the first page, we can just cycle through each review contained in each_review and pick out the “details” element from each review. There are different ways of doing this. Here we will do it by collecting the individual elements in a list by stripping out the text of each of the “details” elements:
info = []
# cycle through all reviews
for theReview in each_review:
# reviewer info
row = theReview.find("div", {"class": "details"}).text.strip()
info.append(row)
print(row)
#print(info)Gabe | 19-24 | Male | On medication for less than 1 month | Patient
Anonymous | 25-34 | Male | On medication for 5 to less than 10 years | Patient
Say no to abili | 35-44 | Male | On medication for 5 to less than 10 years | Patient
SamRS | 45-54 | Female | On medication for 6 months to less than 1 year | Patient
Anonymous | 55-64 | Male | Patient
Alex Adams | 25-34 | Male | On medication for 1 to 6 months | Patient
Roxanne | 65-74 | Transgender | On medication for 2 to less than 5 years | Patient
Roses | 19-24 | Male | On medication for 6 months to less than 1 year | Caregiver
Sara | 25-34 | Female | On medication for less than 1 month | Patient
Kitty | 19-24 | Female | On medication for 2 to less than 5 years | Patient
Scaredmommabear | 7-12 | Male | On medication for less than 1 month | Caregiver
SB09 | Patient
Anonymous | 45-54 | Female | On medication for 2 to less than 5 years | Patient
Anonymous | 13-18 | Transgender | On medication for 1 to 6 months | Patient
DJ | 19-24 | Male | On medication for 1 to 6 months | Patient
Lana | 19-24 | Female | On medication for 1 to less than 2 years | Patient
Elizabeth Gutierrez | 25-34 | Female | On medication for 2 to less than 5 years | Patient
Rhen | 75 or over | Female | On medication for less than 1 month | Patient
Barbara | 65-74 | Female | On medication for 2 to less than 5 years | Patient
Matt | 35-44 | Male | On medication for 1 to 6 months | PatientNow we can just add additional elements to this. For example, we will also want the underlying medical condition for each reviewer. This element is a little more tricky since it has missings - some reviewers don’t list their underlying condition. This is actually not a problem on the first page but it will be on subsequent pages. So we need to flag the missings whenever they exist. We do this by adding an if statement so that the text of the “condition” class is only collected when it exists:
condition = []
info = []
# cycle through all reviews
for theReview in each_review:
# reviewer info
row = theReview.find("div", {"class": "details"}).text.strip()
info.append(row)
# condition
row = theReview.find("strong", {"class": "condition"})
theCondition = "NA"
if row:
theCondition = row.text.strip()
condition.append(theCondition)
print(theCondition)
#print(condition)Condition: Other
Condition: Other
Condition: Bipolar I Disorder with Most Recent Episode Mixed
Condition: Mania associated with Bipolar Disorder
Condition: Additional Medications to Treat Depression
Condition: Schizophrenia
Condition: Additional Medications to Treat Depression
Condition: Other
Condition: Manic-Depression
Condition: Other
Condition: Other
Condition: Other
Condition: Additional Medications to Treat Depression
Condition: Other
Condition: Schizophrenia
Condition: Additional Medications to Treat Depression
Condition: Bipolar I Disorder with Most Recent Episode Mixed
Condition: Additional Medications to Treat Depression
Condition: Bipolar Disorder in Remission
Condition: SchizophreniaOk - loooks good. We are going to add a few more elements that we want to retain and the put the whole thing into a function:
def scrapeThePage(theSoup):
"""This function scrapes one page from WebMD"""
# first grab all reviews on page
each_review = theSoup.find_all("div",{"class": "review-details"})
# initialize lists
condition = []
info = []
comment = []
rating = []
# cycle through reviews
for theReview in each_review:
# condition (making sure to flag missings)
row = theReview.find("strong", {"class": "condition"})
theCondition = "NA"
if row:
theCondition = row.text.strip()
condition.append(theCondition)
# reviewer info
row = theReview.find("div", {"class": "details"}).text.strip()
info.append(row)
# text comment (making sure to flag missings)
row = theReview.find("p",{"class": "description-text"})
theComment = "NA"
if row:
theComment = row.text.strip()
comment.append(theComment)
# rating
row = theReview.find("div",{"class": "overall-rating"}).text.strip()
rating.append(row)
return condition, info, comment, ratingThis function returns four lists containing information for each review. Now we can just call this function for each of all the review pages for the drug we are interested in.
In order to use the function above, we need find the URL for each review page. You can easily figure this out by advancing through the pages on WebMD. The pages are as follows:
https://reviews.webmd.com/drugs/drugreview-64439-abilify-oral?conditionid=&sortval=1&pagenumber=1
https://reviews.webmd.com/drugs/drugreview-64439-abilify-oral?conditionid=&sortval=1&pagenumber=2
https://reviews.webmd.com/drugs/drugreview-64439-abilify-oral?conditionid=&sortval=1&pagenumber=3
and so on up to the last page (page 91). We can recreate this in Python as
num_pages = 92
urls = ['{}?conditionid=&sortval=1&pagenumber={}'.format(base_url, pagenumber) for pagenumber in range(1,num_pages)]All we need to do now is just cycle through all the pages:
num_pages = 92
urls = ['{}?conditionid=&sortval=1&pagenumber={}'.format(base_url, pagenumber) for pagenumber in range(1,num_pages)]
allCondition = []
allInfo = []
allComment = []
allRating = []
for url in urls:
print(url)
page = requests.get(url, headers=headers)
soup = BeautifulSoup(page.content,"lxml")
l1, l2, l3, l4 = scrapeThePage(soup)
allCondition.extend(l1)
allInfo.extend(l2)
allComment.extend(l3)
allRating.extend(l4)
# collect results into dataframe
dict = {'Condition': allCondition, 'Reviewer': allInfo, 'Review': allComment, 'Rating': allRating}
allDataDF = pd.DataFrame(dict) The final dataframe has 1,808 rows - one for each review.
Ok - let’s start with the first point, i.e., how to scrape one page. We pick the first page of reviews. Using Chrome Developer Tools or Selectorgadget, we find that that each user review (including user characteristics) is contained in a class called “review-details”. We start by collecting all these:
# read first page
baseURL <- 'https://www.webmd.com/drugs/drugreview-64439-abilify'
thePage <- read_html(baseURL)
reviews <- thePage %>%
html_nodes(".review-details") The resulting node set has 20 elements - one for each of the user reviews on the first page:
reviews{xml_nodeset (20)}
[1] <div class="review-details">\n<div class="card-header">\n<svg width="20p ...
[2] <div class="review-details">\n<div class="card-header">\n<svg width="20p ...
[3] <div class="review-details">\n<div class="card-header">\n<svg width="20p ...
[4] <div class="review-details">\n<div class="card-header">\n<svg width="20p ...
[5] <div class="review-details">\n<div class="card-header">\n<svg width="20p ...
[6] <div class="review-details">\n<div class="card-header">\n<svg width="20p ...
[7] <div class="review-details">\n<div class="card-header">\n<svg width="20p ...
[8] <div class="review-details">\n<div class="card-header">\n<svg width="20p ...
[9] <div class="review-details">\n<div class="card-header">\n<svg width="20p ...
[10] <div class="review-details">\n<div class="card-header">\n<svg width="20p ...
[11] <div class="review-details">\n<div class="card-header">\n<svg width="20p ...
[12] <div class="review-details">\n<div class="card-header">\n<svg width="20p ...
[13] <div class="review-details">\n<div class="card-header">\n<svg width="20p ...
[14] <div class="review-details">\n<div class="card-header">\n<svg width="20p ...
[15] <div class="review-details">\n<div class="card-header">\n<svg width="20p ...
[16] <div class="review-details">\n<div class="card-header">\n<svg width="20p ...
[17] <div class="review-details">\n<div class="card-header">\n<svg width="20p ...
[18] <div class="review-details">\n<div class="card-header">\n<svg width="20p ...
[19] <div class="review-details">\n<div class="card-header">\n<svg width="20p ...
[20] <div class="review-details">\n<div class="card-header">\n<svg width="20p ...Now we can simply pick out the relevant sub-elements and convert them to text. For reviewer info, review date and reviewer condition we use (having first found the relevant class names using Developer Tools or Selectorgadget)
reviewerInfo <- reviews %>%
html_node(".details") %>%
html_text()
date <- reviews %>%
html_node(".date") %>%
html_text()
conditionInfo <- reviews %>%
html_node(".condition") %>%
html_text()which gives us
reviewerInfo [1] " Gabe | 19-24 | Male | On medication for less than 1 month | Patient "
[2] " Anonymous | 25-34 | Male | On medication for 5 to less than 10 years | Patient "
[3] " Say no to abili | 35-44 | Male | On medication for 5 to less than 10 years | Patient "
[4] " SamRS | 45-54 | Female | On medication for 6 months to less than 1 year | Patient "
[5] " Anonymous | 55-64 | Male | Patient "
[6] " Alex Adams | 25-34 | Male | On medication for 1 to 6 months | Patient "
[7] " Roxanne | 65-74 | Transgender | On medication for 2 to less than 5 years | Patient "
[8] " Roses | 19-24 | Male | On medication for 6 months to less than 1 year | Caregiver "
[9] " Sara | 25-34 | Female | On medication for less than 1 month | Patient "
[10] " Kitty | 19-24 | Female | On medication for 2 to less than 5 years | Patient "
[11] " Scaredmommabear | 7-12 | Male | On medication for less than 1 month | Caregiver "
[12] " SB09 | Patient "
[13] " Anonymous | 45-54 | Female | On medication for 2 to less than 5 years | Patient "
[14] " Anonymous | 13-18 | Transgender | On medication for 1 to 6 months | Patient "
[15] " DJ | 19-24 | Male | On medication for 1 to 6 months | Patient "
[16] " Lana | 19-24 | Female | On medication for 1 to less than 2 years | Patient "
[17] " Elizabeth Gutierrez | 25-34 | Female | On medication for 2 to less than 5 years | Patient "
[18] " Rhen | 75 or over | Female | On medication for less than 1 month | Patient "
[19] " Barbara | 65-74 | Female | On medication for 2 to less than 5 years | Patient "
[20] " Matt | 35-44 | Male | On medication for 1 to 6 months | Patient " date [1] " 9/22/2023 " " 9/10/2023 " " 9/8/2023 " " 8/2/2023 " " 7/29/2023 "
[6] " 7/5/2023 " " 6/5/2023 " " 5/15/2023 " " 5/15/2023 " " 5/15/2023 "
[11] " 5/15/2023 " " 4/29/2023 " " 4/28/2023 " " 4/4/2023 " " 3/30/2023 "
[16] " 3/28/2023 " " 3/21/2023 " " 2/18/2023 " " 2/13/2023 " " 2/9/2023 " conditionInfo [1] " Condition: Other "
[2] " Condition: Other "
[3] " Condition: Bipolar I Disorder with Most Recent Episode Mixed "
[4] " Condition: Mania associated with Bipolar Disorder "
[5] " Condition: Additional Medications to Treat Depression "
[6] " Condition: Schizophrenia "
[7] " Condition: Additional Medications to Treat Depression "
[8] " Condition: Other "
[9] " Condition: Manic-Depression "
[10] " Condition: Other "
[11] " Condition: Other "
[12] " Condition: Other "
[13] " Condition: Additional Medications to Treat Depression "
[14] " Condition: Other "
[15] " Condition: Schizophrenia "
[16] " Condition: Additional Medications to Treat Depression "
[17] " Condition: Bipolar I Disorder with Most Recent Episode Mixed "
[18] " Condition: Additional Medications to Treat Depression "
[19] " Condition: Bipolar Disorder in Remission "
[20] " Condition: Schizophrenia " We also want the actual reviewer comments:
description <- reviews %>%
html_node(".description-text") %>%
html_text()
description [1] "I was prescribed this in the hospital for bipolar depression. It took a couple days to kick in, but when it did, my anxiety immediately worsened to unbearable levels. I couldn't stop blinking and I felt a constant sense of dread. I had trouble working and sleeping. I couldn't even stop it immediately; I had to ween off of it for about two weeks. This could potentially be extremely beneficial, but caution is needed."
[2] "gained weight, tiredness, but it works for psycosis "
[3] "This is the worse Med ever. I dont even know why any Dr. Would script this is 2023. Hair loss weight gain 80lbs sever body and hip aches lack of concentration this drug should be banned for life "
[4] "This medicine has changed my life. It literally fixed my ADD/ADHD, I could feel my head level for the first time in my adult life. I highly recommend the round pills not the football like kind. Round doesnt make me gain weight bc of constant hunger but football kind did. "
[5] "I never had issues with anxiety until I took this crap. still having anxiety even after months of not taking. "
[6] "Worked really well for like 2 months then I got restlessness and couldn't stop moving so bad I couldn't barely drive my car because I was was just exploding with movement and having suicidal thoughts. Read online that it could of been permanent, that would of ruined my life, thankfully I've been off of it and it has slowly went away."
[7] "I am a bipolar woman who has been battling depression and anxiety most of her life. Adding ability to the mix aided me tremendously."
[8] "This medication was a game changer. Prescribed for aggressive out bursts, anxiety, agitation and mood dysregulation/meltdowns associated with Autism. My son says it gives him \"more thinking time\" and he is able to think things through before he becomes overwhelmed and reactive. Used in addition to a low dose antidepressant.\nNo side effects."
[9] "I took 1 dose. I then began to go insane for probably a 24 hour period of anxiety and panic like the world has never seen. A horse tranquilizer couldn't calm me down. It was horrible and so was Caplyta. They both mess with the same brain chemicals dopamine and serotonin. Also Caplyta caused interrupted breathing during sleep. My son thought I was going to die. He told me the next day he checked on me in the middle of the night and I wasn't breathing and then I was. I can't get around very well so he checks on me.Read More Read Less "
[10] "I took this medicine for 2.5 years after having hallucinations, hearing stuff, extreme paranoia and extreme raging episodes. It didn't help at all in the beginning but somewhere in the middle it helped a bit and then it stopped helping lol. Im diagnosed with borderline personality disorder which can give \"psychotic\" symptoms due to extreme emotions so i guess they thought it would help my extreme raging episodes, which it didn't. I got taken off the medicine about 6 months ago due to 2 physical illnesses i have, one being pcos. Nth really changed but i hardcore hallucinated and heard stuff this one night, more than usual. But that could be bc i was in an extreme physical stress state bc i got broken up with. In conclusion, its useless ??Read More Read Less "
[11] "My 7 year old took this medication for 2 days and is neck started to bother him at school. The teacher dismissed him by the time me got home it was really hurting bad. I took him to the ER. but the time me got there he was dropped face on one side hard to talk and drooling and in pain. Never again will we take this. "
[12] "I've been on abilify before and recently went on it again. I've noticed people in reviews talking about being restless and I did experience some of that this second time but my Dr put me on a low dose of propranolol to counter it and that fixed it. Abilify really helps my depression and OCD. I can think clearer and it makes me more calm. I have major depression with psychotic tendencies and it helps with my hallucinations and paranoia as well. :) I do want to eat a lot but I learned the first time to pack little healthy snacks and drink plenty of water and it helps curb it some,plus exercise. Read More Read Less "
[13] "I was on the Abilify injection monthly for like 4 years. It made me put on so weight that I had never gained in my lifetime. It has steroids in it. I finally got off of in summer of 2020."
[14] "I never wanted to be on these meds and they have made me more suicidal and they have not helped. they make me feel tired all the time. it feels like my eyes are coming out of my head sometimes. i just dont feel real and this med makes me feel 10 times worse"
[15] "It made me paranoid, cry for no reason, very anxious and have weird scary thoughts"
[16] "I was put on this medication when i was diagnosed with depression, anxiety and anorexia. I started on 1mg and went up to 10mg. I stayed on 10mg for a year and that was the worst year of my life. I struggled with binge eating - gained 60lbs in under a year, spent money recklessly, felt suicidal but didnt have the energy to act on it, was tired, had no motivation to do things and became very impulsive with self harm. The day i chose to stop taking it is what i think of the best day of my life. After i stopped taking it, i was told by the pyschatrist that 40% of people he prescribes it to has had an issue with compulsive/impulsive behaviours such as binge eating, gambling, excessive spending. If it works for you im glad, but please be aware of it. If you experience any behaviours that are not normal to you, talk to your dr about it and mention that you are on this drug. Read More Read Less "
[17] "Terrible medication, always causes episodes and I had terrible anxiety with it. I feel like this medication almost got me killed. Never taking this medication again. "
[18] "I take 2 mg before bed. Wake up feeling normal and happy for the first time in 2 yrs. Getting off the small dose xanax. I love it."
[19] "I've taken Abilify to augment bupropion for Bipolar Disorder and associated Major Depression for years now and it's been exceptionally effective.\nI especially like it because I've had no side effects unlike other antipsychotics.\nI highly recommend despite the negative reviews from a small number of users."
[20] "Worked for 3 months. Waste of time. You think your all better then it's like taking candy and it doesnt do anything anymore. Not worth 768 dollars. " Finally, we also want to retain the star rating for each review:
rating <- reviews %>%
html_node(".overall-rating") %>%
html_text()
rating [1] " Overall rating 1.3 " " Overall rating 4.3 " " Overall rating 1.0 "
[4] " Overall rating 5.0 " " Overall rating 1.0 " " Overall rating 2.3 "
[7] " Overall rating 4.3 " " Overall rating 4.7 " " Overall rating 1.0 "
[10] " Overall rating 3.0 " " Overall rating 1.0 " " Overall rating 4.0 "
[13] " Overall rating 1.0 " " Overall rating 2.3 " " Overall rating 1.3 "
[16] " Overall rating 2.3 " " Overall rating 1.0 " " Overall rating 5.0 "
[19] " Overall rating 5.0 " " Overall rating 2.0 "We only care about the number of the text string. There are different ways of getting at that - here we use a regular expression to extract the number of the text string:
rating <- reviews %>%
html_node(".overall-rating") %>%
html_text() %>%
as.data.frame() %>%
rename(rating=".") %>%
mutate(rating = as.numeric(gsub("[^0-9.]", "", rating)))
rating rating
1 1.3
2 4.3
3 1.0
4 5.0
5 1.0
6 2.3
7 4.3
8 4.7
9 1.0
10 3.0
11 1.0
12 4.0
13 1.0
14 2.3
15 1.3
16 2.3
17 1.0
18 5.0
19 5.0
20 2.0At this point we have figured out how to scrape everything we need from one page. Let’s put all this into a function that we can call repeatedly:
ScrapeThePage <- function(theURL){
reviews <- theURL %>%
html_nodes(".review-details")
reviewerInfo <- reviews %>%
html_node(".details") %>%
html_text()
date <- reviews %>%
html_node(".date") %>%
html_text()
conditionInfo <- reviews %>%
html_node(".condition") %>%
html_text()
rating <- reviews %>%
html_node(".overall-rating") %>%
html_text() %>%
as.data.frame() %>%
rename(rating=".") %>%
mutate(rating = as.numeric(gsub("[^0-9.]", "", rating)))
description <- reviews %>%
html_node(".description-text") %>%
html_text()
df <- data.frame(info = reviewerInfo,
date = date,
condition = conditionInfo,
rating = rating$rating,
text = description,
stringsAsFactors = F)
return(df)
}Now we have to find out how many pages of reviews we need to scrape. You can either look this up manually on the web site or you can calculate it automatically by finding out how many reviews there are in total and knowing how many there are per page.
# get numnber of reviews in total
GetNumberReviews <- read_html(baseURL) %>%
html_nodes("label.count") %>%
html_text() %>%
.[1]
NumberReviews <- as.numeric(str_split_fixed(GetNumberReviews," ",5)[1,4])
# find out how many pages to scrape
ReviewPerPage <- 20
NumberPages <- floor(NumberReviews/ReviewPerPage)
eps = NumberPages - (NumberReviews/ReviewPerPage) # correcting if not divisible by 20
if (!eps==0) {NumberPages <- NumberPages+1}Ok - now we are done - we can scrape all pages:
## run the scraper
allReviews <- NULL
for (thePageIndex in 1:NumberPages){
cat('page ', thePageIndex)
pageURL <- read_html(paste0(baseURL,'?conditionid=&sortval=1&pagenumber=',thePageIndex))
theReviews <- ScrapeThePage(pageURL)
allReviews <- bind_rows(allReviews,
theReviews)
}At this point, I would put all the code into one function:
ScrapeDrugWebMD <- function(baseURL){
GetNumberReviews <- read_html(baseURL) %>%
html_nodes("label.count") %>%
html_text() %>%
.[1]
NumberReviews <- as.numeric(str_split_fixed(GetNumberReviews," ",5)[1,4])
ReviewPerPage <- 20
NumberPages <- floor(NumberReviews/ReviewPerPage)
eps = NumberPages - (NumberReviews/ReviewPerPage)
if (!eps==0) {NumberPages <- NumberPages+1}
## run the scraper
allReviews <- NULL
for (thePageIndex in 1:NumberPages){
cat('Scraping page ', thePageIndex, '\n')
pageURL <- read_html(paste0(baseURL,'?conditionid=&sortval=1&pagenumber=',thePageIndex))
theReviews <- ScrapeThePage(pageURL)
allReviews <- bind_rows(allReviews,
theReviews)
}
return(allReviews)
}We can now run the scraper on as many drugs as we like:
## Abilify
theURL <- 'https://www.webmd.com/drugs/drugreview-64439-abilify'
theReviews <- ScrapeDrugWebMD(theURL)
write_rds(theReviews,'data/Abilify.rds')
## Adderall
theURL <- 'https://www.webmd.com/drugs/drugreview-63164-adderall-xr-oral'
theReviews <- ScrapeDrugWebMD(theURL)
write_rds(theReviews,'data/Adderall.rds')
## Celexa
theURL <- 'https://www.webmd.com/drugs/drugreview-8603-celexa-oral'
theReviews <- ScrapeDrugWebMD(theURL)
write_rds(theReviews,'data/Celexa.rds')Using AI tools to Aid in Scraping
 AI tools like ChatGPT (and others) offer significant advantages in the realm of web scraping. As the examples above illustrate, it can be somewhat tedious to identify the correct html components on complex websites and one often ends up proceeding in a “trial-and-error” manner. AI tools can automate this extraction process, efficiently parsing through vast amounts of html code and isolating relevant information, thereby saving substantial time and manual effort. AI tools can be designed to understand and navigate through complex website structures, handling variations in design and layout, and can adapt to changes in website structures, ensuring that the web scraping process remains resilient and effective.
AI tools like ChatGPT (and others) offer significant advantages in the realm of web scraping. As the examples above illustrate, it can be somewhat tedious to identify the correct html components on complex websites and one often ends up proceeding in a “trial-and-error” manner. AI tools can automate this extraction process, efficiently parsing through vast amounts of html code and isolating relevant information, thereby saving substantial time and manual effort. AI tools can be designed to understand and navigate through complex website structures, handling variations in design and layout, and can adapt to changes in website structures, ensuring that the web scraping process remains resilient and effective.
Here is a simple and easy way to scrape a website using ChatGPT. Suppose we want to scrape the reviews for a drug on WebMD and that we don’t know how to write raw Python code like we did above (or simply don’t have the time!). Let’s use ChatGPT to help us.
Suppose we want to scrape user reviews of the weight loss drug Ozempic. These can be found on WebMD here. Since ChatGPT is not able to connect to websites we must first download the webpage and then upload it to ChatGPT. You can download a webpage by simply clicking Ctrl+S. We then upload the file along with our prompt. In order to help ChatGPT to locate the correct html elements to scrape, it is recommended to actually explicitly tell the AI what you want (this is strictly speaking not neccesary since AIs like ChatGPT can learn what elements you want by you giving it feedback). Suppose we seek reviewer name, reviewer condition and review text. A simple prompt could then be
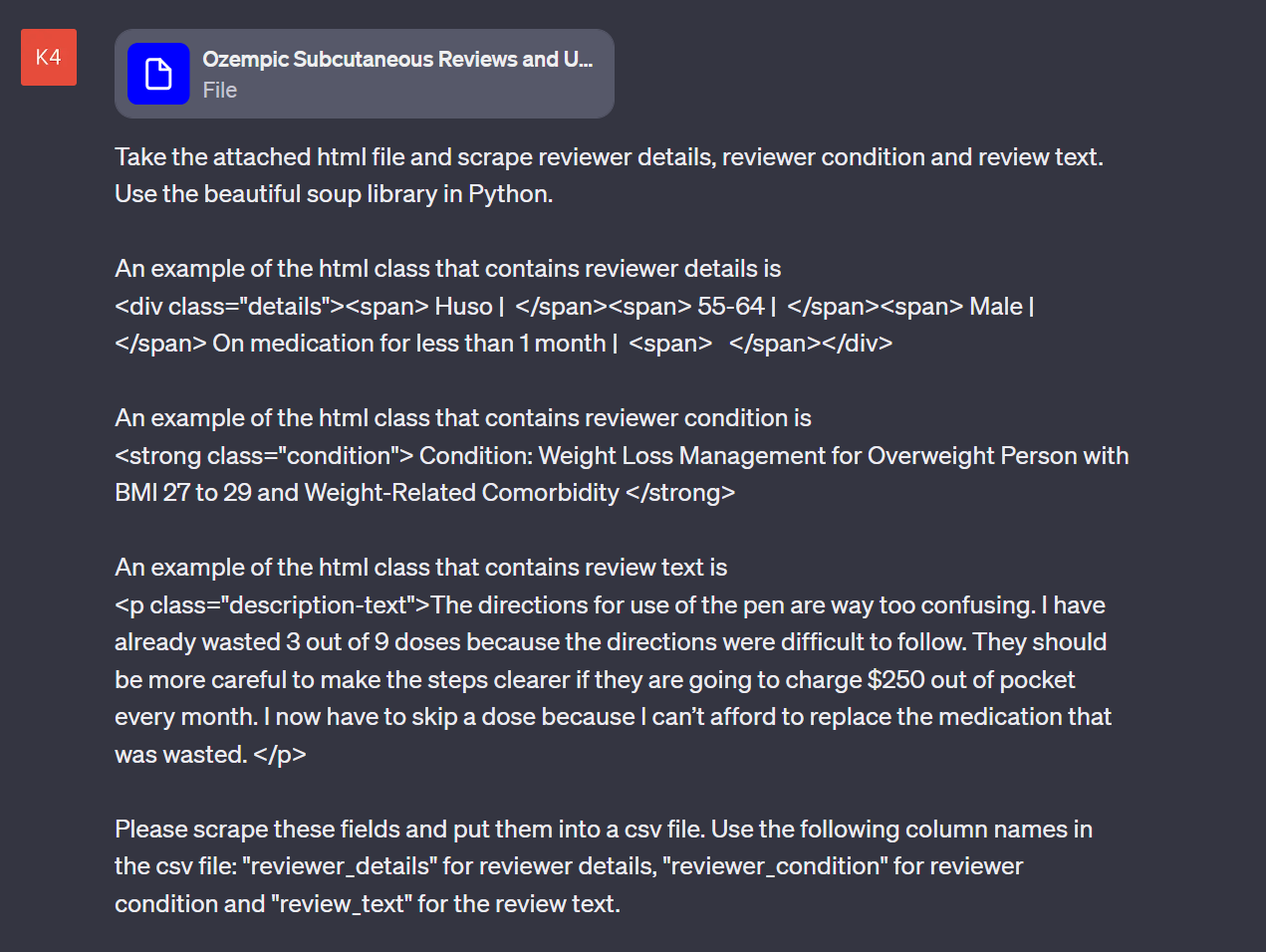
The reply from ChatGPT was
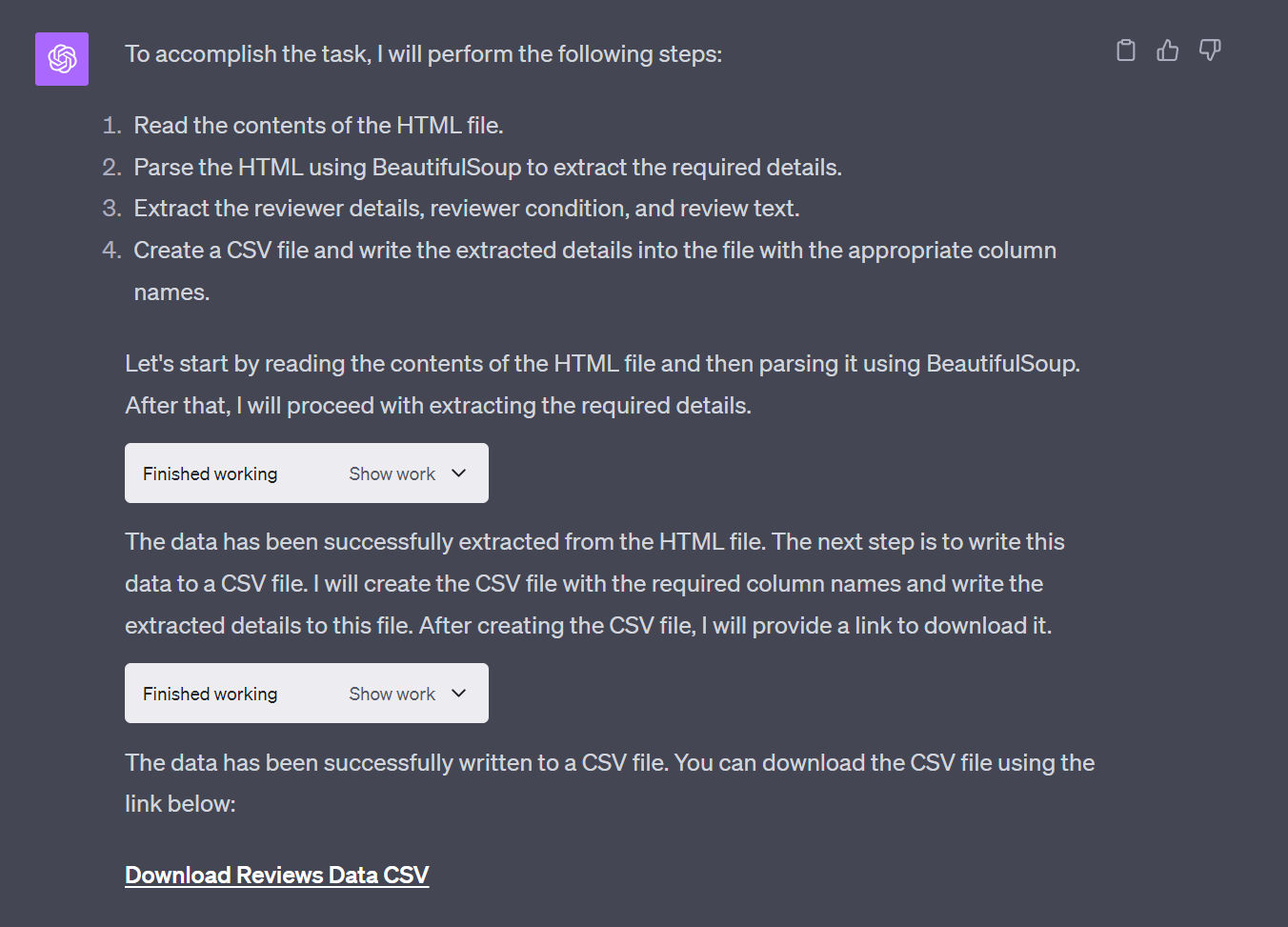
The csv file can then be downloaded. Easy.
As we know from above, WebMD reviews are distributed across multiple pages and above ChatGPT only scraped the first page (the one we uploaded). What do we do if we want to scrape ALL the reviews for Ozempic? In this case there are 21 such pages. You have two strategies here: (1) you can download each of the 21 pages and then upload all of them to ChatGPT or (2) ask ChatGPT to rewrite the code above to span all pages and then just run the code yourself (locally). In this case we are going to go with (2) (recall again that these hacks are needed since ChatGPT can’t access the internet itself).
We can try the following prompt:
The reply from ChatGPT was

The code that ChatGPT returned was
import requests
from bs4 import BeautifulSoup
import csv
# Define the base URL
base_url = 'https://reviews.webmd.com/drugs/drugreview-174491-ozempic-subcutaneous?conditionid=&sortval=1&page={}&next_page=true'
# Initialize the list to store the extracted details
extracted_data = []
# Loop over all the 21 pages
for page in range(1, 22):
print(f"Processing page {page}...")
# Construct the URL for the current page
url = base_url.format(page)
# Send a GET request to the server and get the content of the web page
response = requests.get(url)
# Check if the request was successful
if response.status_code == 200:
# Parse the HTML content of the page using BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Extract the required details from the current page
for detail_div, condition_strong, description_p in zip(
soup.find_all('div', class_='details'),
soup.find_all('strong', class_='condition'),
soup.find_all('p', class_='description-text')):
# Extract and store the details
reviewer_details = ' '.join([span.get_text(strip=True) for span in detail_div.find_all('span')])
reviewer_condition = condition_strong.get_text(strip=True).replace('Condition: ', '')
review_text = description_p.get_text(strip=True)
extracted_data.append({
'reviewer_details': reviewer_details,
'reviewer_condition': reviewer_condition,
'review_text': review_text
})
else:
print(f"Failed to retrieve page {page}. Status code: {response.status_code}")
# Write the extracted data to a CSV file
csv_file_path = 'all_reviews_data.csv'
with open(csv_file_path, 'w', newline='', encoding='utf-8') as file:
fieldnames = ['reviewer_details', 'reviewer_condition', 'review_text']
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(extracted_data)
print("Data has been successfully written to", csv_file_path)We can then run this code locally.