import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import datetime
# get raw data
taxi = pd.read_csv('data/yellow_tripdata_2015-06.csv')
# transformations for visualizations
taxi['pickupDateTime'] = pd.to_datetime(taxi['tpep_pickup_datetime'])
taxi['dropoffDateTime'] = pd.to_datetime(taxi['tpep_dropoff_datetime'])
taxi['tripDuration'] = (taxi['dropoffDateTime'] - taxi['pickupDateTime']).dt.total_seconds()/60
taxi['pickupDay'] = taxi['pickupDateTime'].dt.day
taxi['pickupDate'] = taxi['pickupDateTime'].dt.date
taxi['pickupHour'] = taxi['pickupDateTime'].dt.hour
taxi['weekDay'] = taxi['pickupDateTime'].dt.weekday
taxi['weekDay2'] = taxi['pickupDateTime'].dt.strftime('%A')
taxi['paymentType'] = taxi['payment_type'].map({1: 'Credit Card',
2: 'Cash',
3: 'No Charge',
4: 'Other'})Basic Data Visualization in R and Python
 Visualizations bring data to life. A good visualization will give you new insights and will often lead to new ideas for additional analyses or visualizations. As humans we are much better at processing visual information than numeric information - both in terms of comprehension and speed. So unless you can think of any reason otherwise, you should should always present your raw data AND the results of any analysis you have done as a visualization.
Visualizations bring data to life. A good visualization will give you new insights and will often lead to new ideas for additional analyses or visualizations. As humans we are much better at processing visual information than numeric information - both in terms of comprehension and speed. So unless you can think of any reason otherwise, you should should always present your raw data AND the results of any analysis you have done as a visualization.
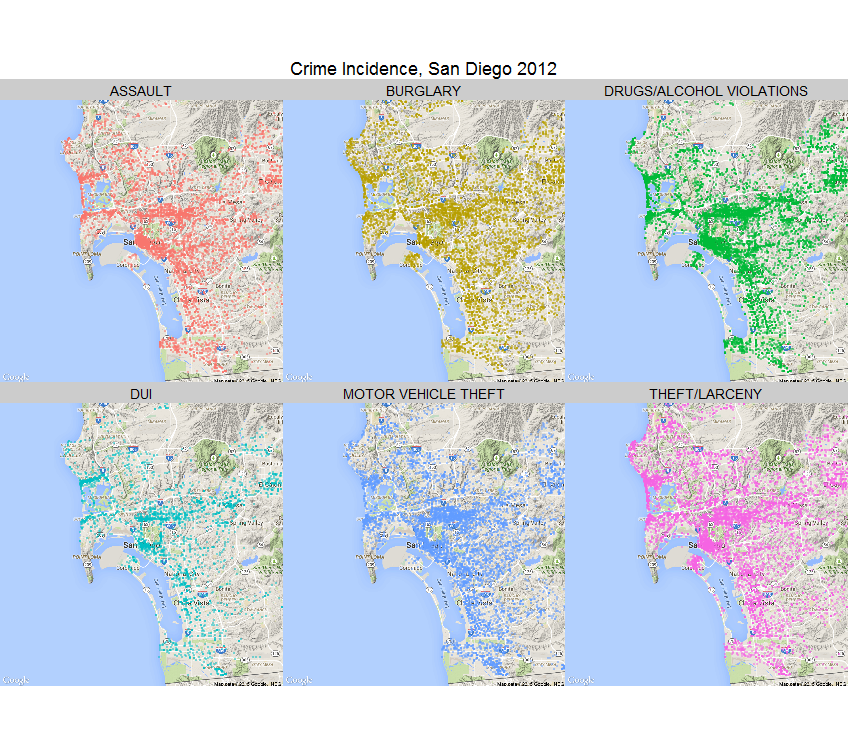
One of the real strengths of both R and Python is the ability to easily visualize even very complex data. See the map on the right? This shows incidents of 6 types of crimes in San Diego for the year 2012. This map shows both the geographical dispersion of different crimes and their actual incidence. You can produce this map with one line of code (you will see how in the maps section). You can even make interactive maps allowing the user obtain further information by clicking on the map.
In this section we will focus on using the powerful ggplot2 library in R and the seaborn library in Python. When you mastered this you will have a wide range of visualization tools at your disposal with very little coding effort.
You can download the code and data for this module by using the Dropbox file transfer link https://www.dropbox.com/t/vL52OAVBBF1Xqr8h.
Case Study: New York Taxi Cabs

This dataset contains information on every single trip taken with a yellow New York City taxi cab in the month of June, 2015. This is over 12 million trips! You can download data in raw format for other months of the year, green cabs and limousine rides here. The New York data doesn’t contain an individual taxi id code so you cannot link trips for the same cab driver. However, there are data for other cities where this is possible, e.g., Chicago (you can find the raw Chicago data here).
In Python the standard visualization libraries for exploratory analysis is Seaborn and its lower level cousin matplotlib. You can think of Seaborn as being a user-friendly version of matplotlib. We start by importing those libraries long with pandas and datetime - the main library for working with date/time stamps. We also read in the data and make a few transformations for use in later visualizations.
Let’s start by learning about different aspects of the number of taxi trips.
Number of Trips
We start by looking at the number of trips for each day of the month using a bar plot
plt.figure(figsize=(15, 8))
pl = sns.countplot(x='pickupDay', data=taxi)
pl.set(title='Taxi Pickups by Day of Month', xlabel = 'Day')
plt.show()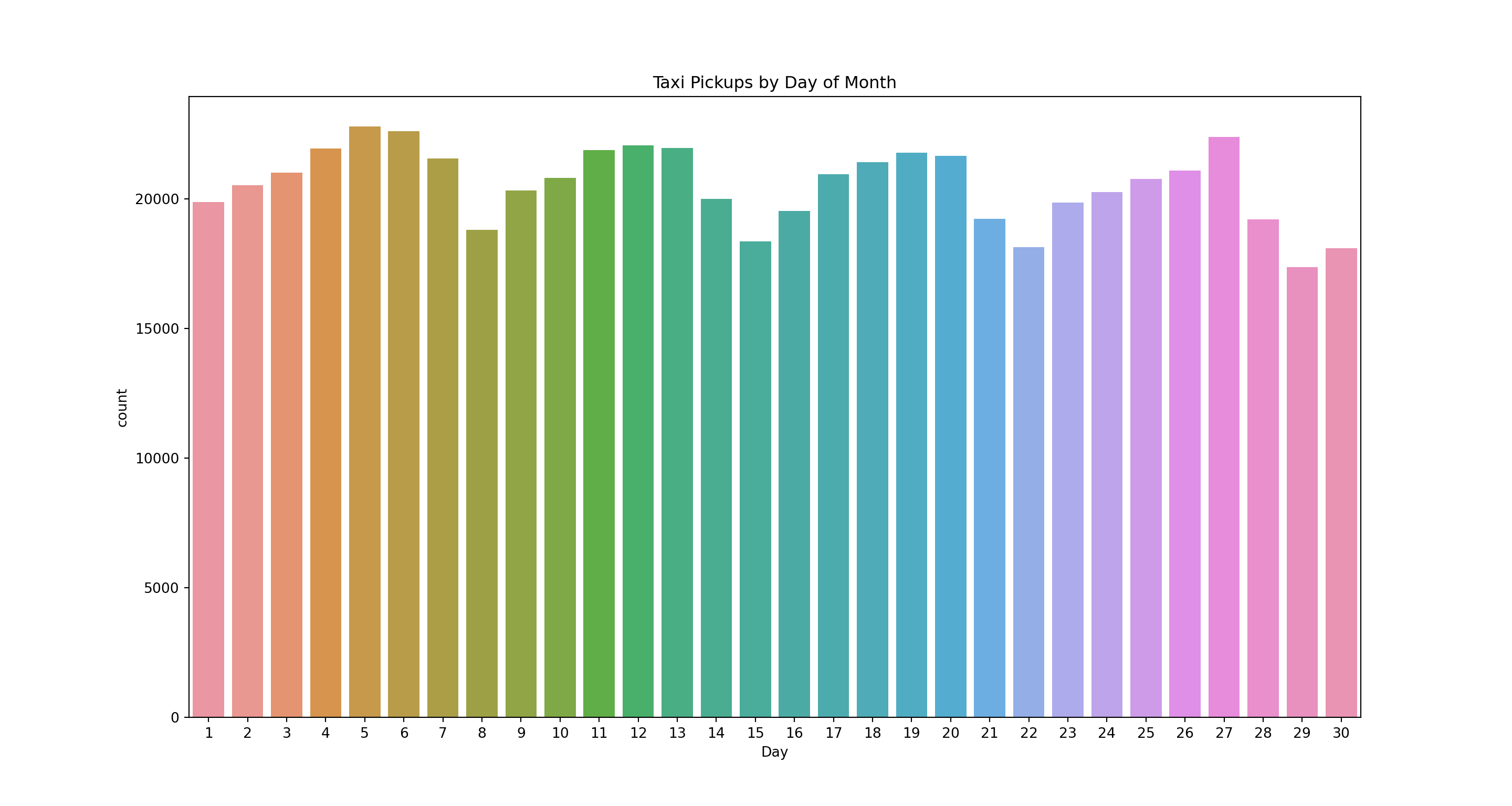
This produces a simple bar chart with counts of the number of rides (or rows in the data) for each value of pickupDay. The chart clearly shows a weekday effect repeated throughout the month.
Is the pattern the same for cash trips only?
sns.countplot(x='pickupDay', data=taxi[taxi['paymentType']=='Cash'])
pl = sns.countplot(x='pickupDay', data=taxi[taxi['paymentType']=='Cash'])
pl.set(title='Taxi Pickups by Day of Month\nCash Trips Only', xlabel = 'Day')
plt.show()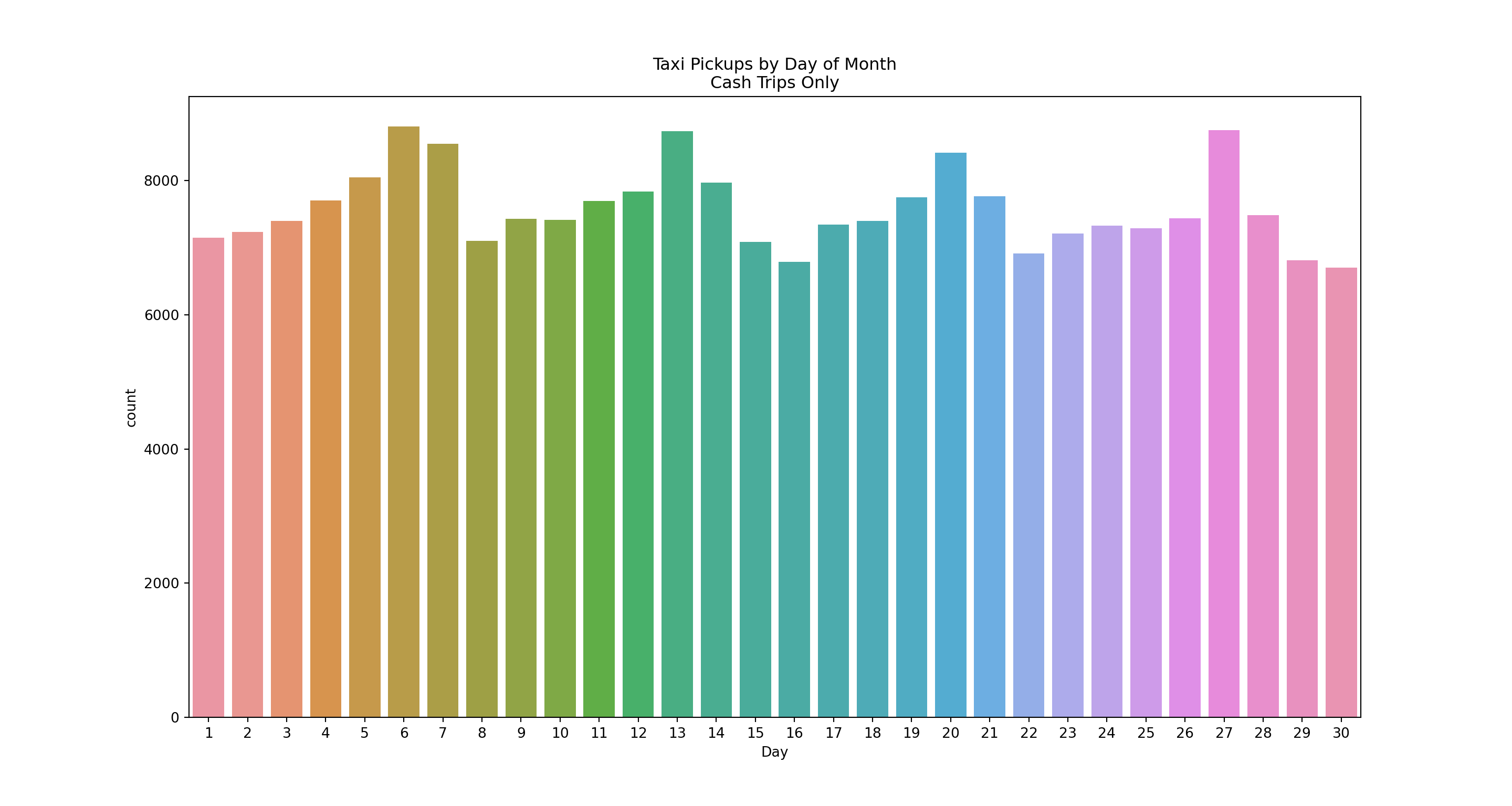
Again we see weekday effects but the peaks are higher than compared to all trips above. It’s a bit hard to compare the two plots. How about we plot the main payment types - credit card and cash - on the same bar chart? That’s pretty straightforward by using the hue option to plot separate bars for each payment type
paymentTypes = ['Credit Card','Cash']
pl = sns.countplot(x='pickupDay', data=taxi[taxi.paymentType.isin(paymentTypes)],
hue = 'paymentType')
pl.set(title='Taxi Pickups by Day and Payment Type', xlabel = 'Day')
plt.show()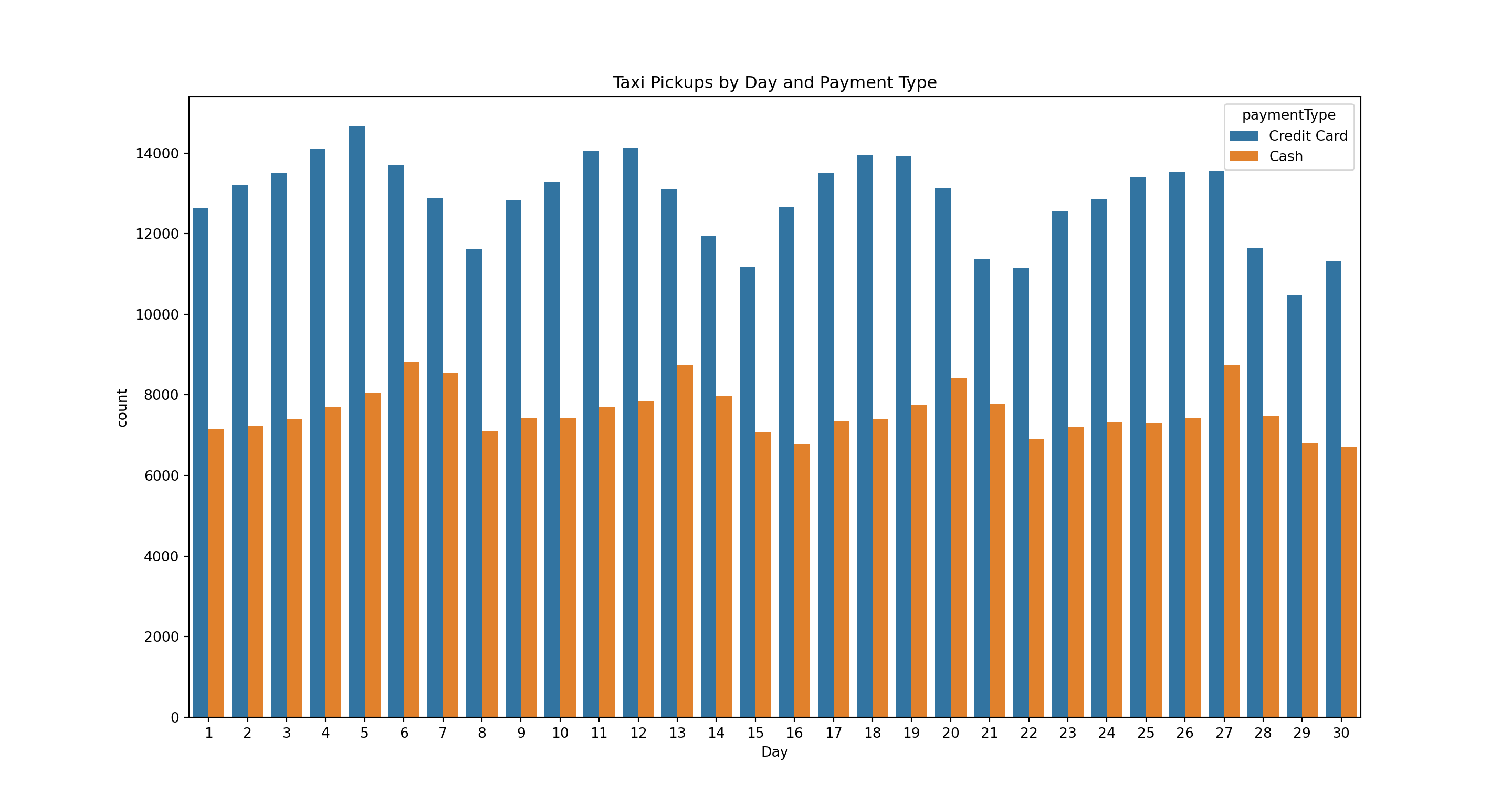
There are many more credit card trips than cash trips. Furthermore, the peaks appear on different weekdays. We can’t tell what these weekdays are - we will look at that below.
How about trips throughout hour of the day?
pl = sns.countplot(x='pickupHour', data=taxi)
pl.set(title='Taxi Pickups by Hour of Day', xlabel = 'Hour')
plt.show()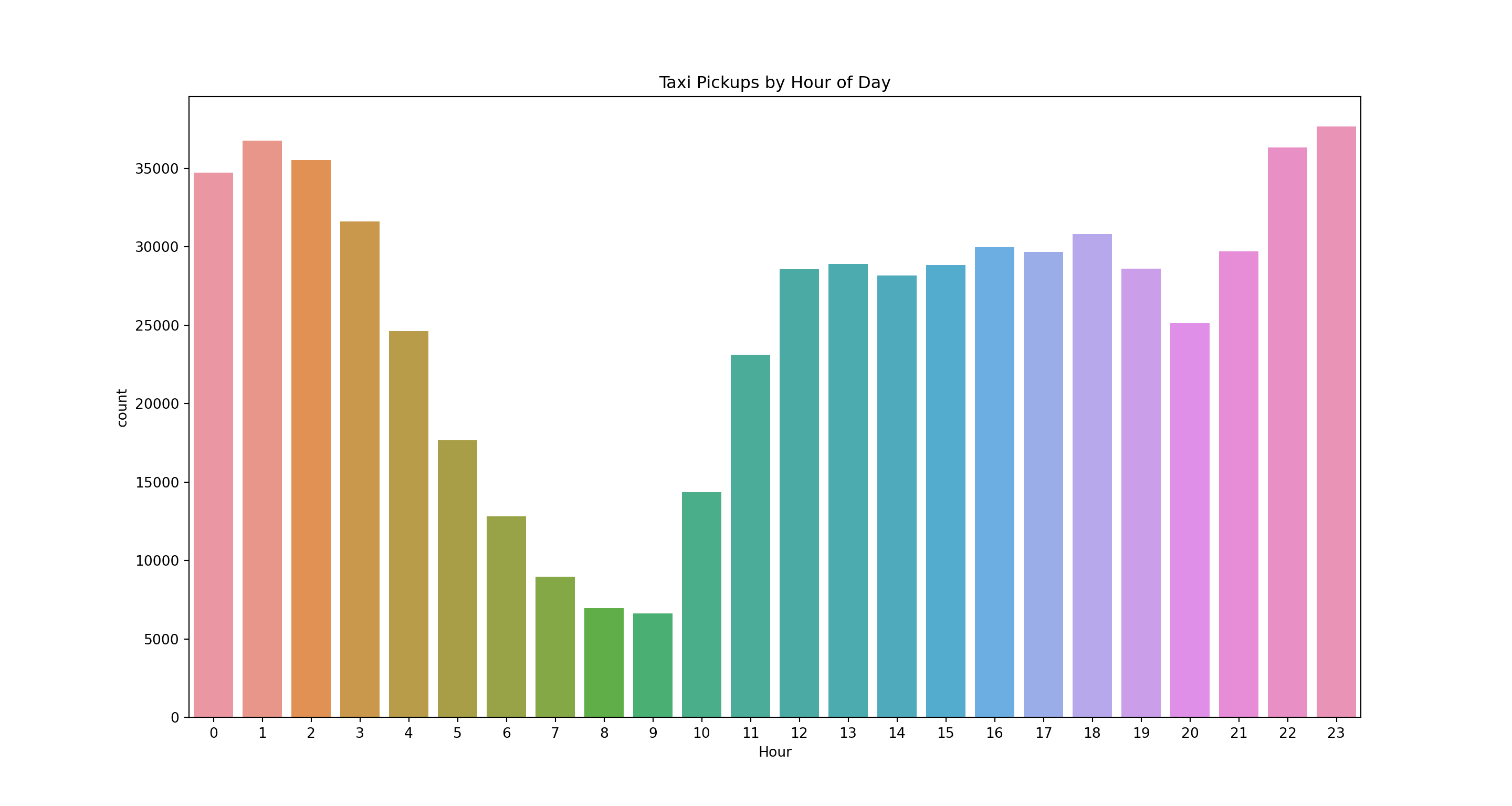
Between 8am and 3pm there is a stable and roughly constant number of rides. Trip demand then increases between 6pm and 10pm. Above we saw that, overall, there were substantially more credit card rides than cash rides. Is this true throughout the day?
Let’s see how trip counts vary by hour of day and payment type
pl = sns.countplot(x='pickupHour', data=taxi[taxi.paymentType.isin(paymentTypes)],
hue = 'paymentType')
pl.set(title='Taxi Pickups by Hour of Day and Payment Type', xlabel = 'Hour')
plt.show()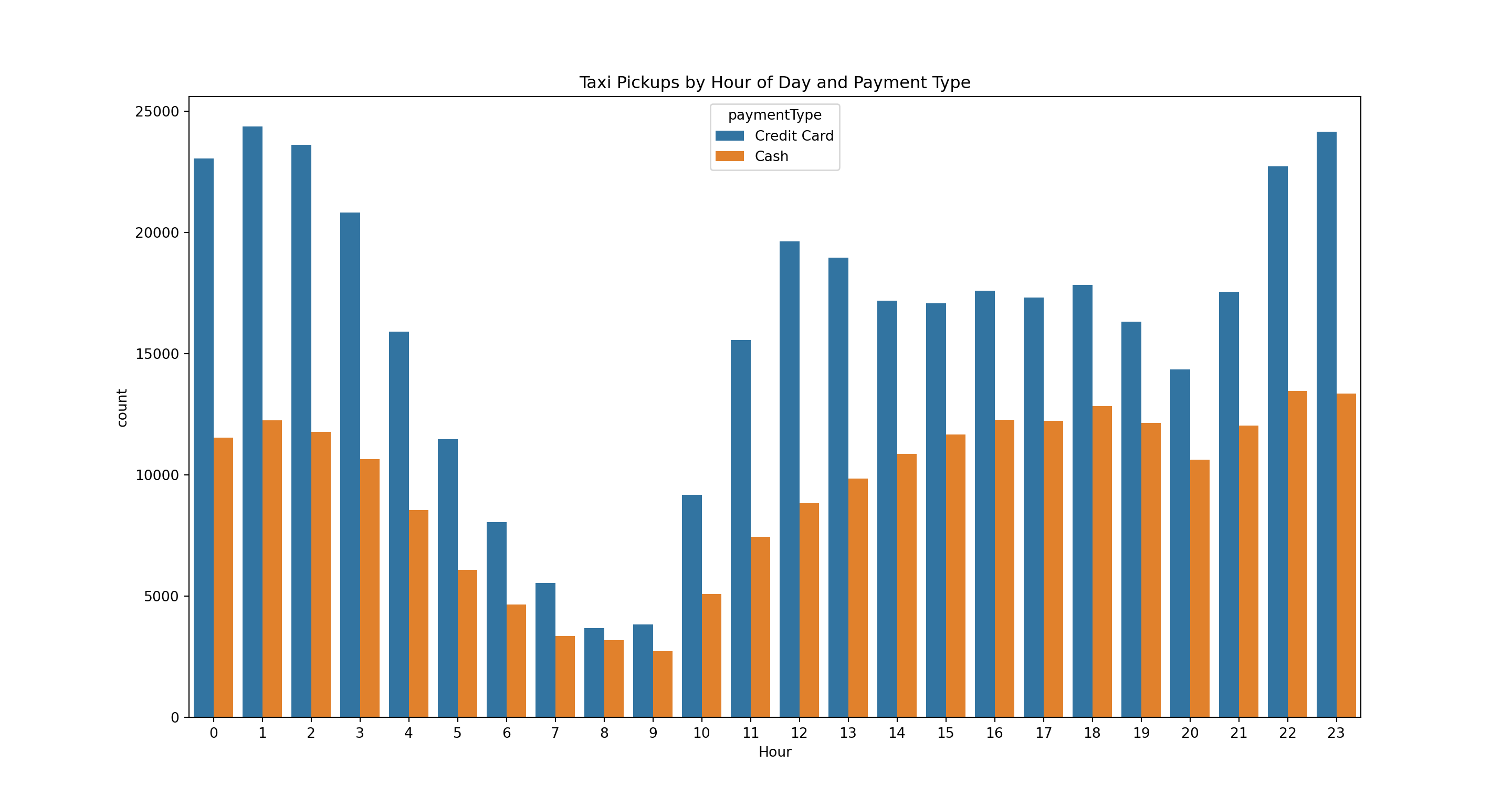
We see a large variation in the ratio of payment types throughout the day. For example, in the evening there are about twice as many credit card trips compared to cash trips. However, in the early morning it is close to 50-50.
How do the number of trips vary by weekday? We want to make sure that the days of the week are ordered correctly in the plot so we enforce the ordering of the x-axis using the order option
weekDayOrder = ['Monday','Tuesday','Wednesday','Thursday','Friday','Saturday','Sunday']
pl = sns.countplot(x='weekDay2', data=taxi, order=weekDayOrder)
pl.set(title='Taxi Pickups by Weekday', xlabel = 'Day of Week')
plt.show()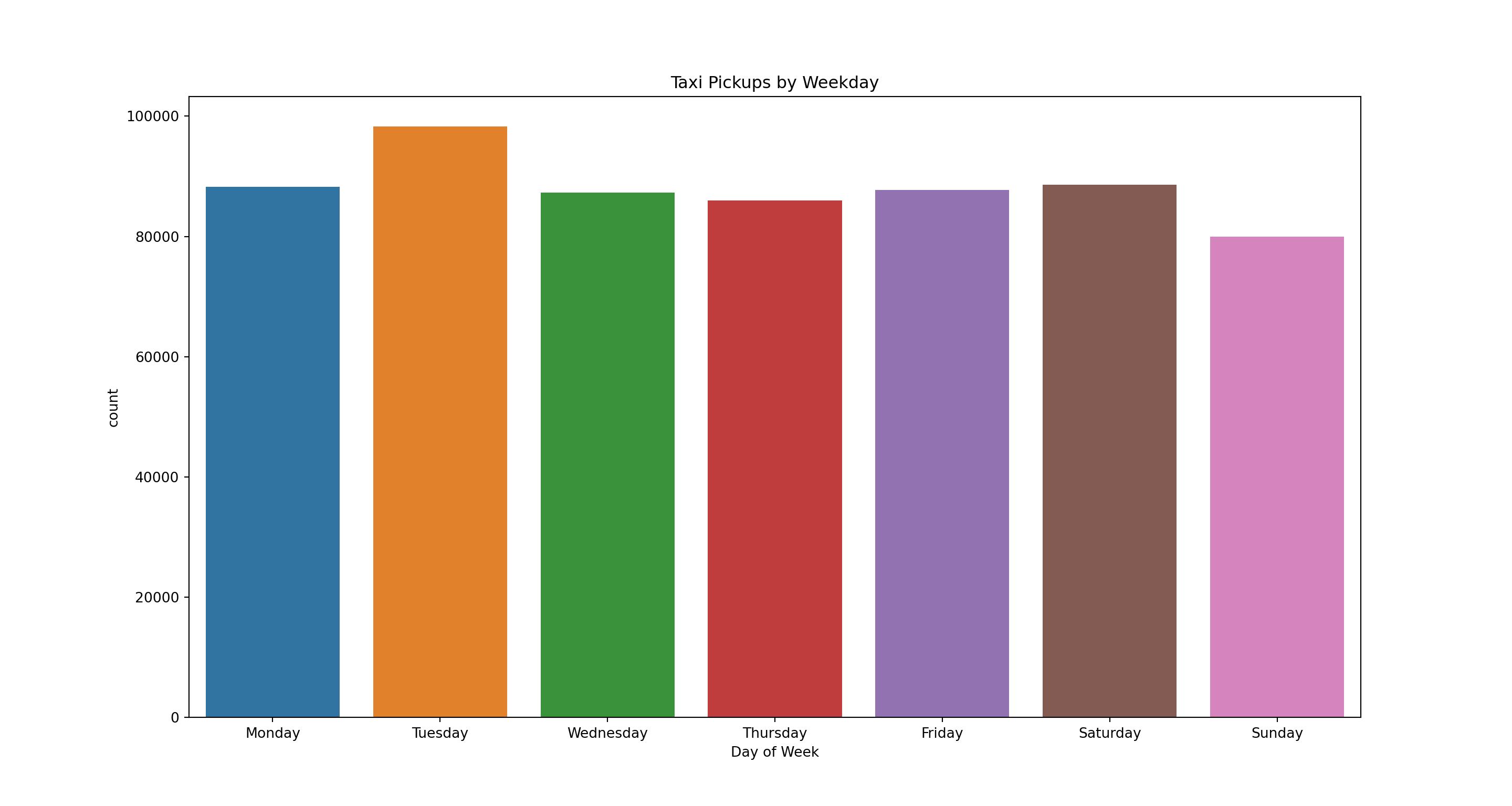
Substantially more trips on Tuesdays? That sounds weird. As discussed in the R example of this data, this happens because there aren’t the same number of weekdays during a single month (e.g., there are 5 Tuesdays and only 4 Wednesdays for the month of June 2015). To correct this - and get a better sense of how trips vary by weekday - we calculate the average number of trips by weekday using a groupby command and the plot the averages
df = taxi.pickupDate.value_counts().reset_index()
df['weekDay'] = pd.to_datetime(df['pickupDate']).dt.strftime('%A')
avgTrips = df.groupby(['weekDay'])['count'].mean().reset_index()
pl = sns.barplot(x='weekDay', y = 'count',
order=['Monday','Tuesday','Wednesday','Thursday','Friday','Saturday','Sunday'],
data=avgTrips)
pl.set(title='Average Taxi Pickups by Weekday', xlabel = 'Day', ylabel = 'Number of Trips')
plt.show()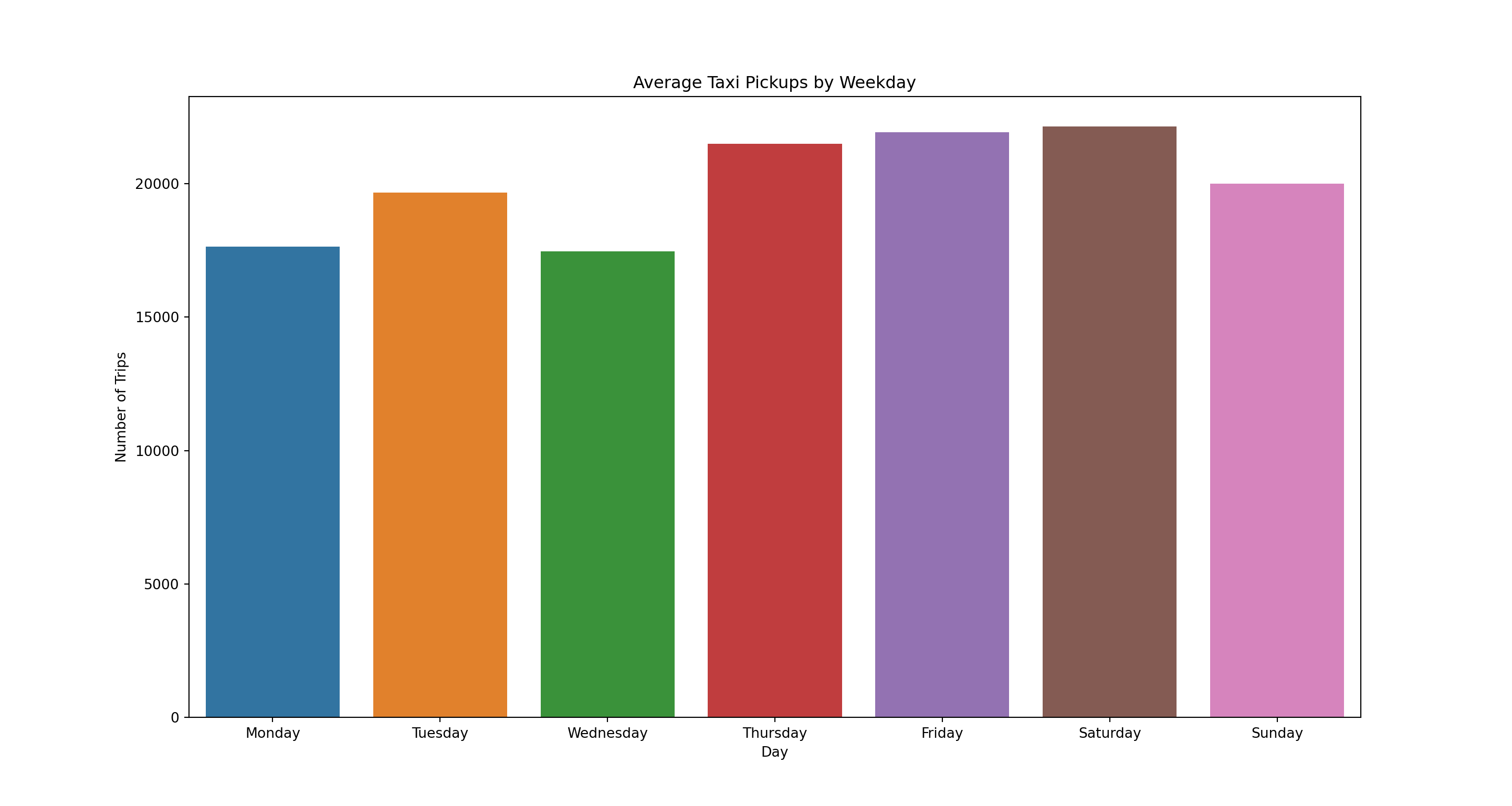
We see that Fridays and Saturdays have the most number of trips on average.
To highlight day-to-day variations we could go with a line or points plot instead
dayCountsDF = taxi.pickupDay.value_counts().reset_index(name='Count')
dayCountsDF.head() pickupDay Count
0 5 22798
1 6 22618
2 27 22396
3 12 22067
4 13 21960pl = sns.lineplot(x='pickupDay', y = 'Count', marker="o", data=dayCountsDF)
pl.set(title='Taxi Pickups by Day of Month', xlabel = 'Day', ylabel = 'Number of Trips')
plt.show()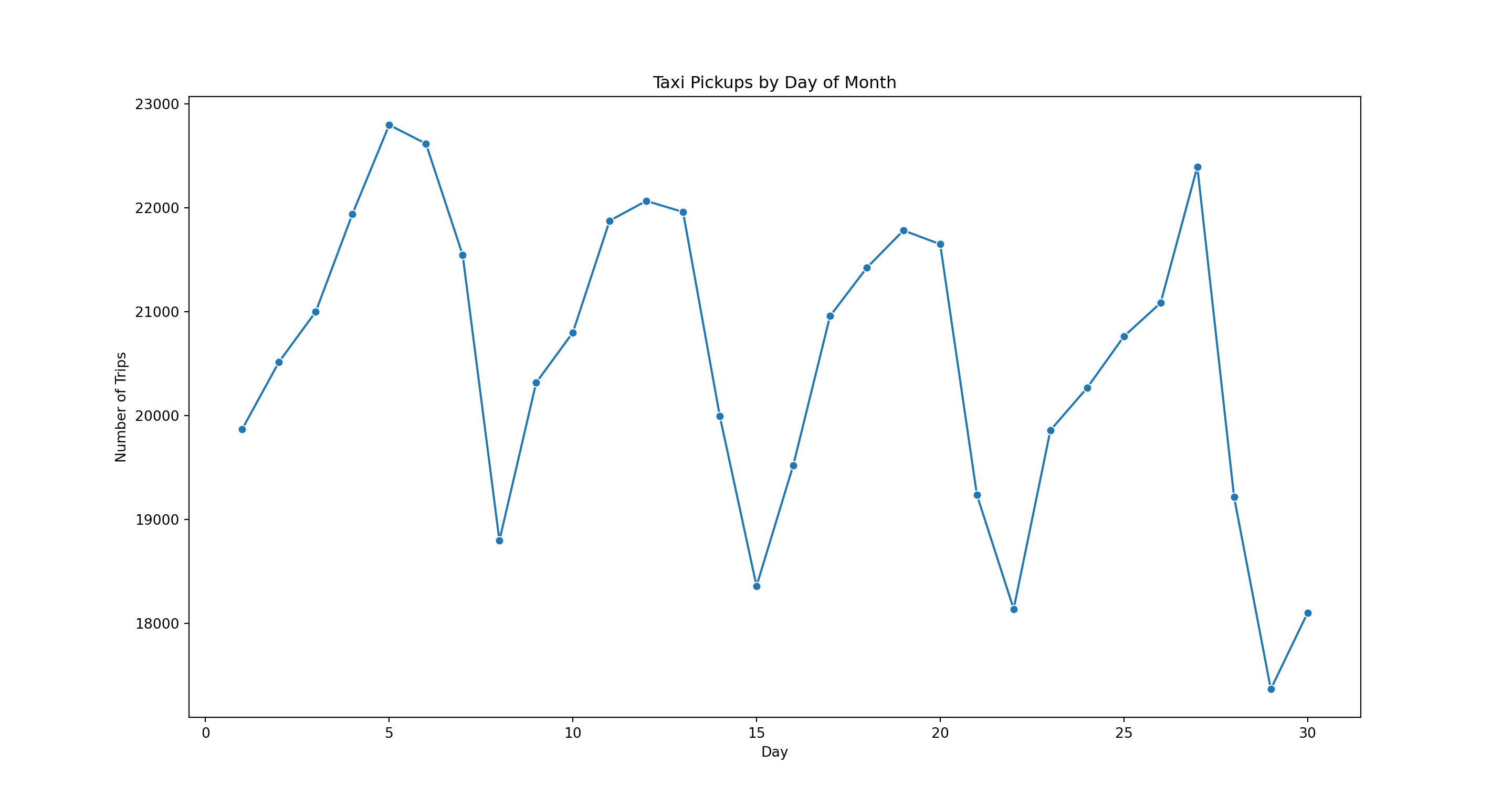
Here it is easier to ascertain the variation in trip counts throughout the month as compared to the bar plot. Similar if we are interested in comparing trips and payment type for the month
paymentTypes = ['Credit Card','Cash']
dayPaymentDF = taxi[taxi.paymentType.isin(paymentTypes)].value_counts(["pickupDay", "paymentType"]).reset_index(name="Count")
pl = sns.lineplot(x='pickupDay', y = 'Count', hue = 'paymentType',marker="o", data=dayPaymentDF)
pl.set(title='Taxi Pickups by Day of Month and Payment', xlabel = 'Day', ylabel = 'Number of Trips')
plt.show()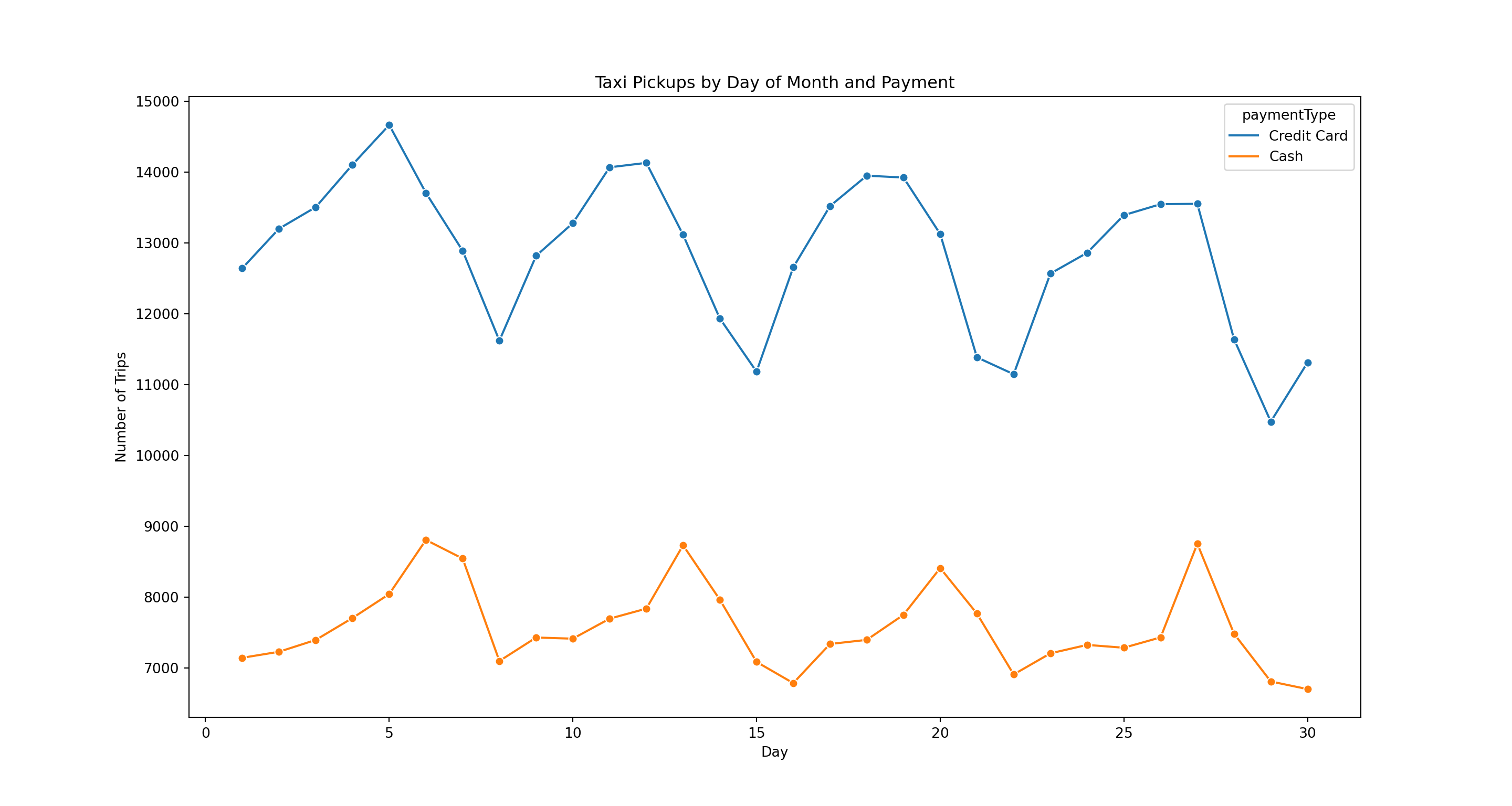
Trip Duration Let’s now turn to visualizing the duration of trips. What is the overall distribution of trip durations? We can use a histogram (where we trim the data for the extreme outliers - see the discussion of this under the R example)
maxDur = 120
pl = sns.histplot(data=taxi[(taxi.tripDuration <= maxDur) & (taxi.tripDuration > 0)], x='tripDuration')
pl.set(title='Distribution of Trip Durations', xlabel = 'Minutes')
plt.show()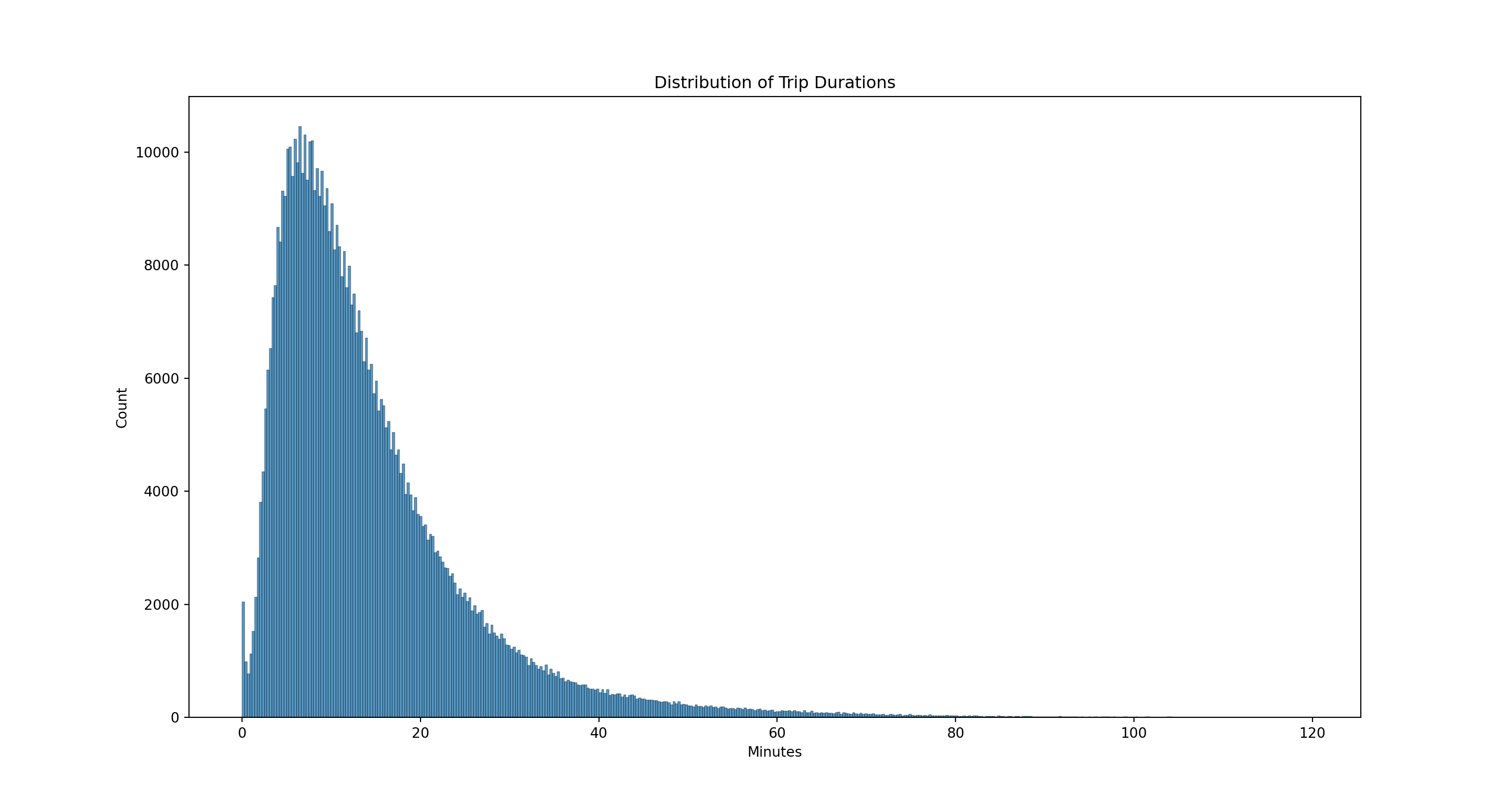
How do trip durations vary by day of month? Since this is a very skewed distribution we will use the median rather than the mean to represent a “typical” trip for each day. We starting by using a groupby command to get the median duration for each day and then plot that using a line plot
durDay = taxi.groupby(['pickupDay'])['tripDuration'].median().reset_index()
pl = sns.lineplot(x='pickupDay', y = 'tripDuration', marker="o", data=durDay)
pl.set(title='Trip Duration by Day of Month', xlabel = 'Day', ylabel = 'Median Duration of Trips (mins)')
plt.show()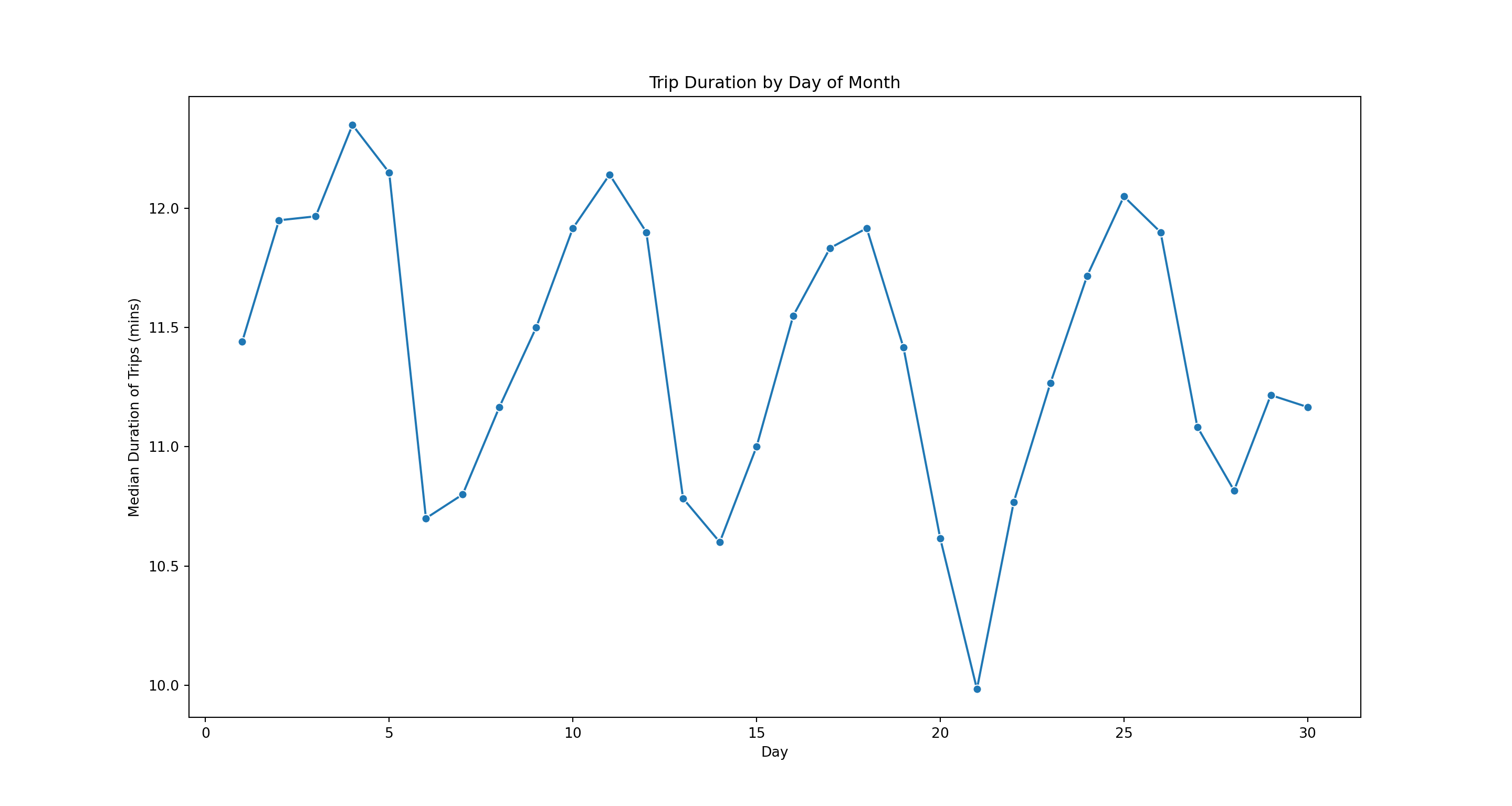
Here is median duration by day of week
durDay = taxi.groupby(['weekDay2'])['tripDuration'].median().reset_index()
durDay['weekDay2'] = pd.Categorical(durDay['weekDay2'],
categories=weekDayOrder,
ordered=True)
pl = sns.lineplot(x='weekDay2', y = 'tripDuration', marker="o", data=durDay)
pl.set(title='Trip Duration by Day of Week', xlabel = 'Day', ylabel = 'Median Duration of Trips (mins)')
plt.show()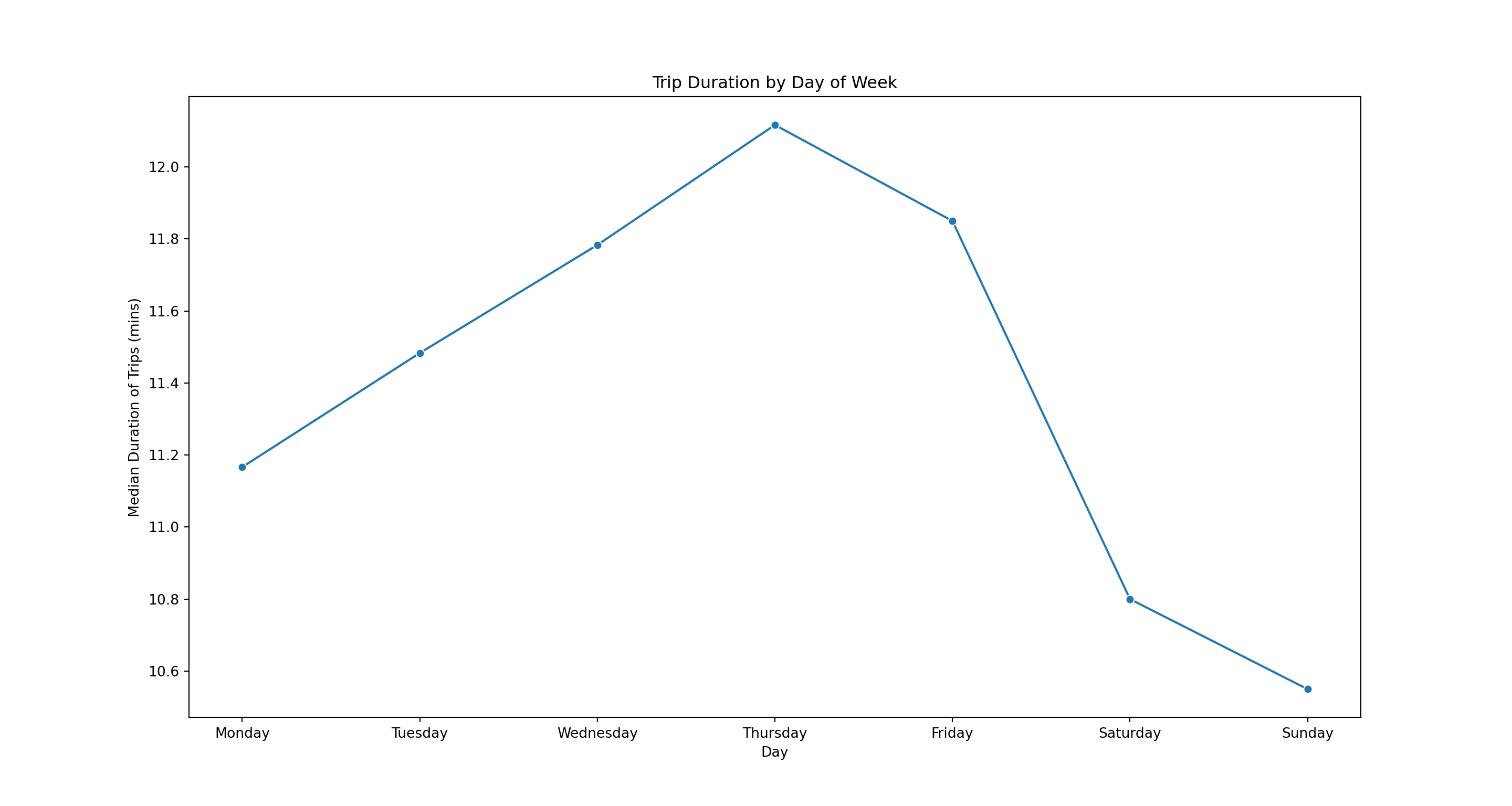
In terms of duration, the longest trips happen mid-week, while the shortest are on weekends.
Let’s look at duration by weekday and hour of day. Let’s first do a version where we superimpose the hourly line for each weekday
durDayHour = taxi.groupby(['weekDay2','pickupHour'])['tripDuration'].median().reset_index()
durDayHour['weekDay2'] = pd.Categorical(durDayHour['weekDay2'],
categories=weekDayOrder,
ordered=True)
pl = sns.lineplot(x='pickupHour', y = 'tripDuration', hue='weekDay2', marker="o", data=durDayHour)
pl.set(title='Trip Duration by Day of Week', xlabel = 'Day', ylabel = 'Median Duration of Trips (mins)')
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.) # put legend outside plot area
plt.show()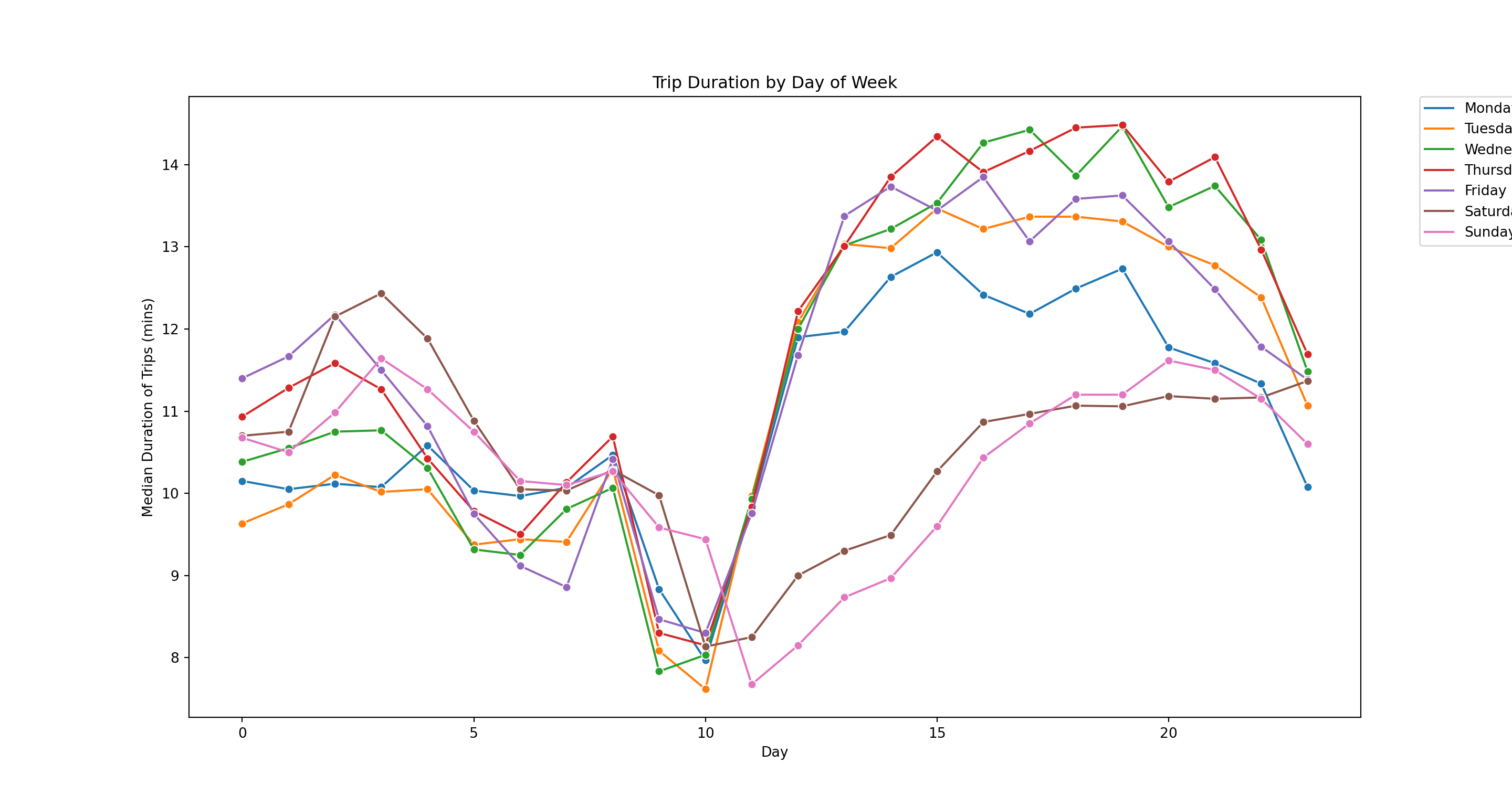
Here we clearly see how weekend days stand out. An alternative is to make sure of the FacetGrid option in Seaborn to create a “small multiples” plot
g = sns.FacetGrid(durDayHour, hue="weekDay2", col="weekDay2",sharey=True,col_wrap=3,height=4.5, aspect=1)
g = g.map(sns.lineplot, "pickupHour", "tripDuration")
g.add_legend()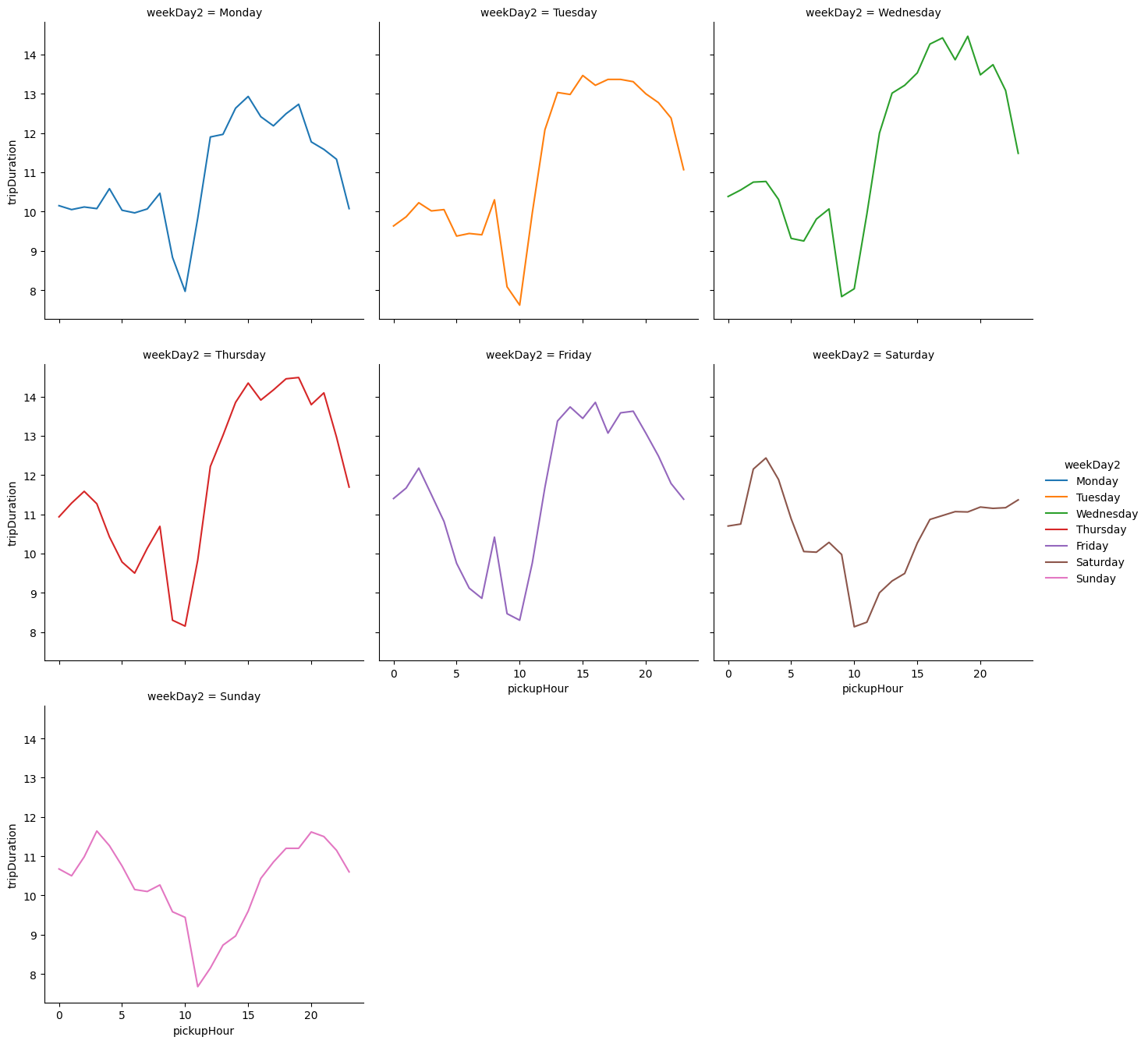
Here we impose the same y-axis scaling on all plots with the sharey=True option.
The ggplot2 library is one of the gems of R. The syntax for producing plots may appear at bit strange at first, but once you get it, you will be producing beautiful and insightful visualizations in no time. With ggplot2 you create visualizations by adding layers to a plot. The ggplot2 is part of the tidyverse library that we always import in an R session so you don’t need to separately import it.
- Any plot in ggplot2 consists of - Data: what you want to plot, duh! - Aesthetics: which variables go on the x-axis, y-axis, colors, styles etc. - Style of plot: Bar, scatter, line etc. These are called plot layers in ggplot and are specified using the syntax geom_layer, e.g., geom_point, geom_line, geom_histogram etc.
We start by loading the tidyverse, and a couple of other helpful libraries that we will rely on below and - of course - the data. We first apply a few transformations using the mutate function
library(tidyverse)
library(lubridate)
library(forcats)
library(scales)
taxi <- read_csv('data/yellow_tripdata_2015-06.csv')
taxi <- taxi %>%
mutate(weekday = wday(tpep_dropoff_datetime,label=TRUE,abbr=TRUE),
hour.trip.start = factor(hour(tpep_pickup_datetime)),
day = factor(mday(tpep_dropoff_datetime)),
trip.duration = as.numeric(difftime(tpep_dropoff_datetime,tpep_pickup_datetime,units="mins")),
trip.speed = ifelse(trip.duration >= 1, trip_distance/(trip.duration/60), NA),
payment_type_label = fct_recode(factor(payment_type),
"Credit Card"="1",
"Cash"="2",
"No Charge"="3",
"Other"="4"))Warning: package 'tidyverse' was built under R version 4.1.3Warning: package 'ggplot2' was built under R version 4.1.3Warning: package 'tibble' was built under R version 4.1.3Warning: package 'stringr' was built under R version 4.1.3Warning: package 'forcats' was built under R version 4.1.3-- Attaching core tidyverse packages ------------------------ tidyverse 2.0.0 --
v dplyr 1.1.1.9000 v readr 2.0.2
v forcats 1.0.0 v stringr 1.5.0
v ggplot2 3.4.2 v tibble 3.2.1
v lubridate 1.8.0 v tidyr 1.1.4
v purrr 0.3.4
-- Conflicts ------------------------------------------ tidyverse_conflicts() --
x dplyr::filter() masks stats::filter()
x dplyr::lag() masks stats::lag()
i Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsWarning: package 'scales' was built under R version 4.1.3
Attaching package: 'scales'
The following object is masked from 'package:purrr':
discard
The following object is masked from 'package:readr':
col_factor
Rows: 616247 Columns: 19-- Column specification --------------------------------------------------------
Delimiter: ","
chr (1): store_and_fwd_flag
dbl (16): VendorID, passenger_count, trip_distance, pickup_longitude, picku...
dttm (2): tpep_pickup_datetime, tpep_dropoff_datetime
i Use `spec()` to retrieve the full column specification for this data.
i Specify the column types or set `show_col_types = FALSE` to quiet this message.Number of Trips
We can start by looking at the total number of cab rides. For example, total number by day of the month
ggplot(data=taxi, aes(x=day)) + geom_bar()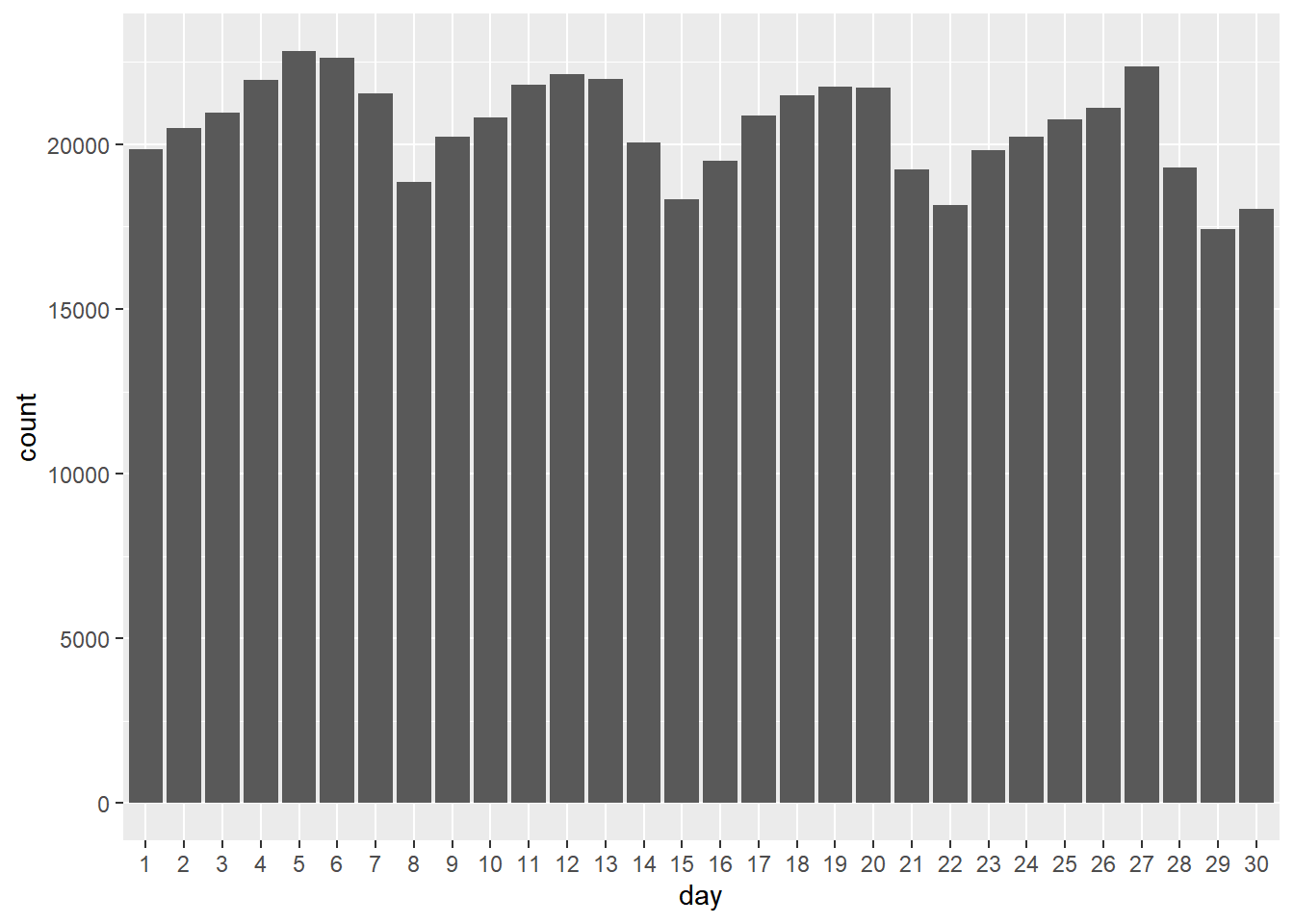
This produces a simple bar chart with counts of the number of rides (or rows in the data) for each value of day. The command aes means “aesthetic” in ggplot. Plot aesthetics are used to tell R what should be plotted, which colors or shapes to use etc. You can also use the “chain” syntax from in conjunction with ggplot. For example, the command
taxi %>%
ggplot(aes(x=day)) + geom_bar()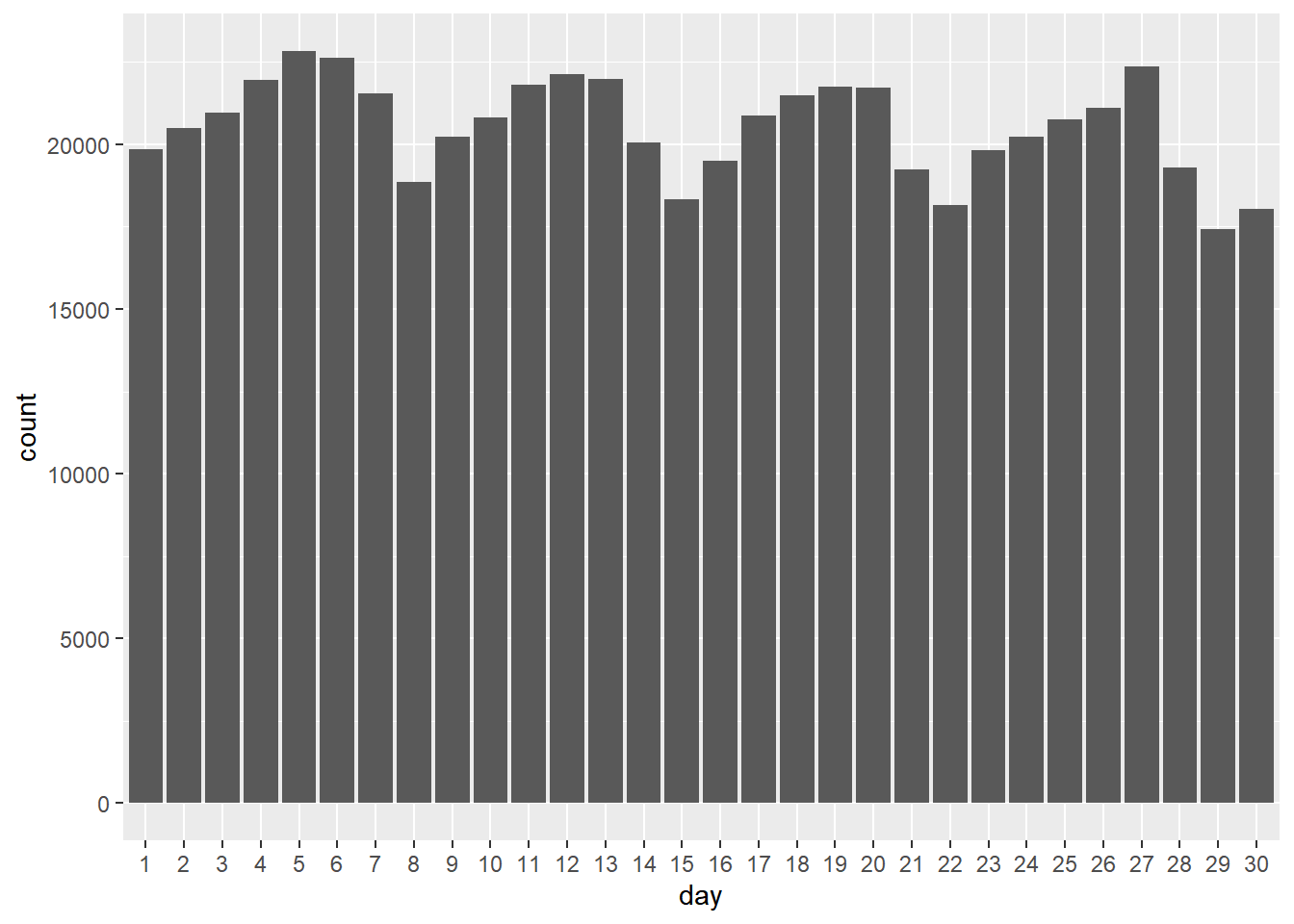
will produce the exaxt same plot. This is quite useful since you now have all the usual tools available to use prior to calling ggplot. For example, suppose you only wanted trips paid with cash. Then you could simply insert a filter statement prior to the plot command
taxi %>%
filter(payment_type_label=='Cash') %>%
ggplot(aes(x=day)) + geom_bar()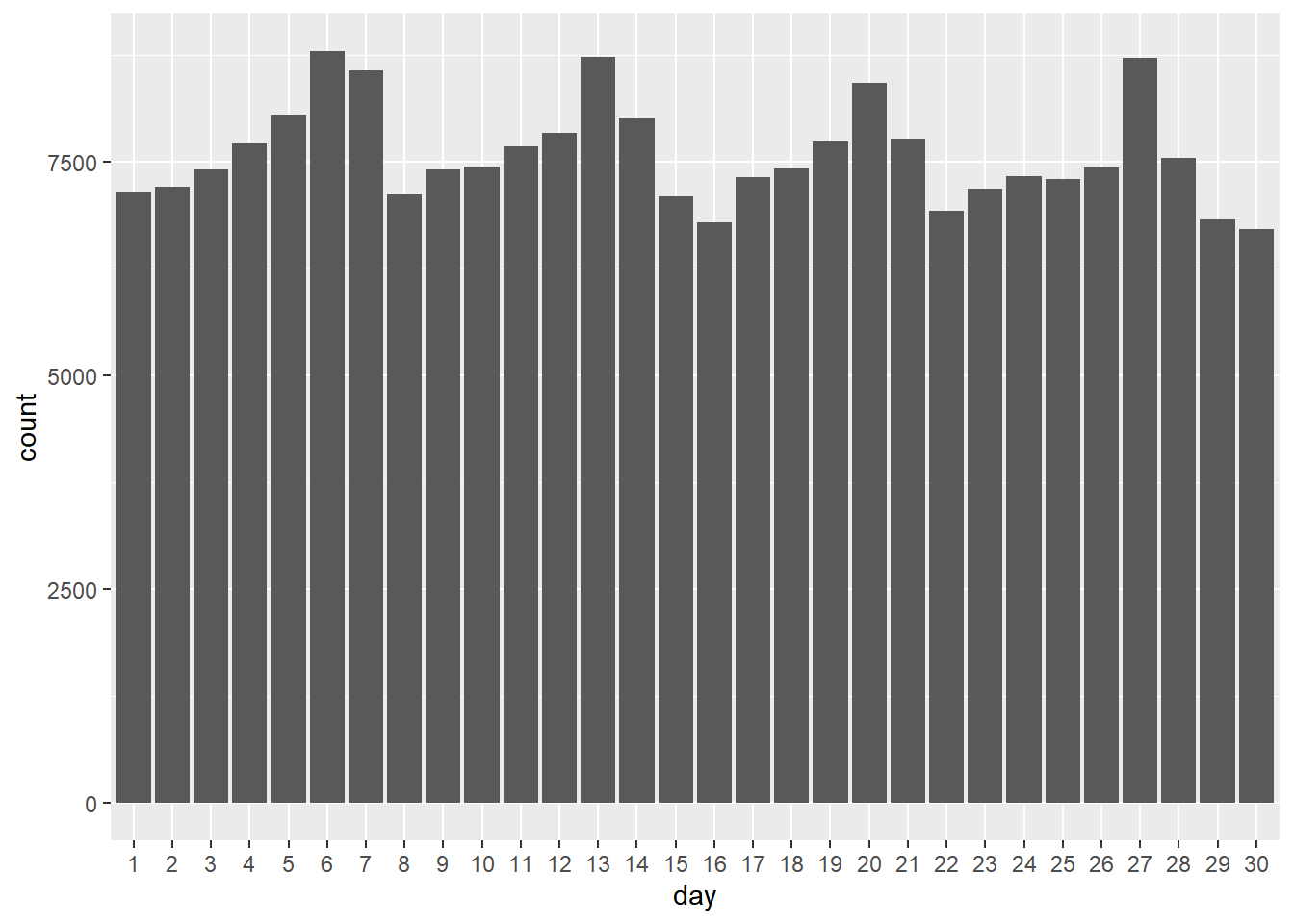
Let’s compare the number of credit and cash rides
taxi %>%
filter(payment_type_label %in% c('Credit Card','Cash')) %>%
ggplot(aes(x=day,fill=payment_type_label)) + geom_bar()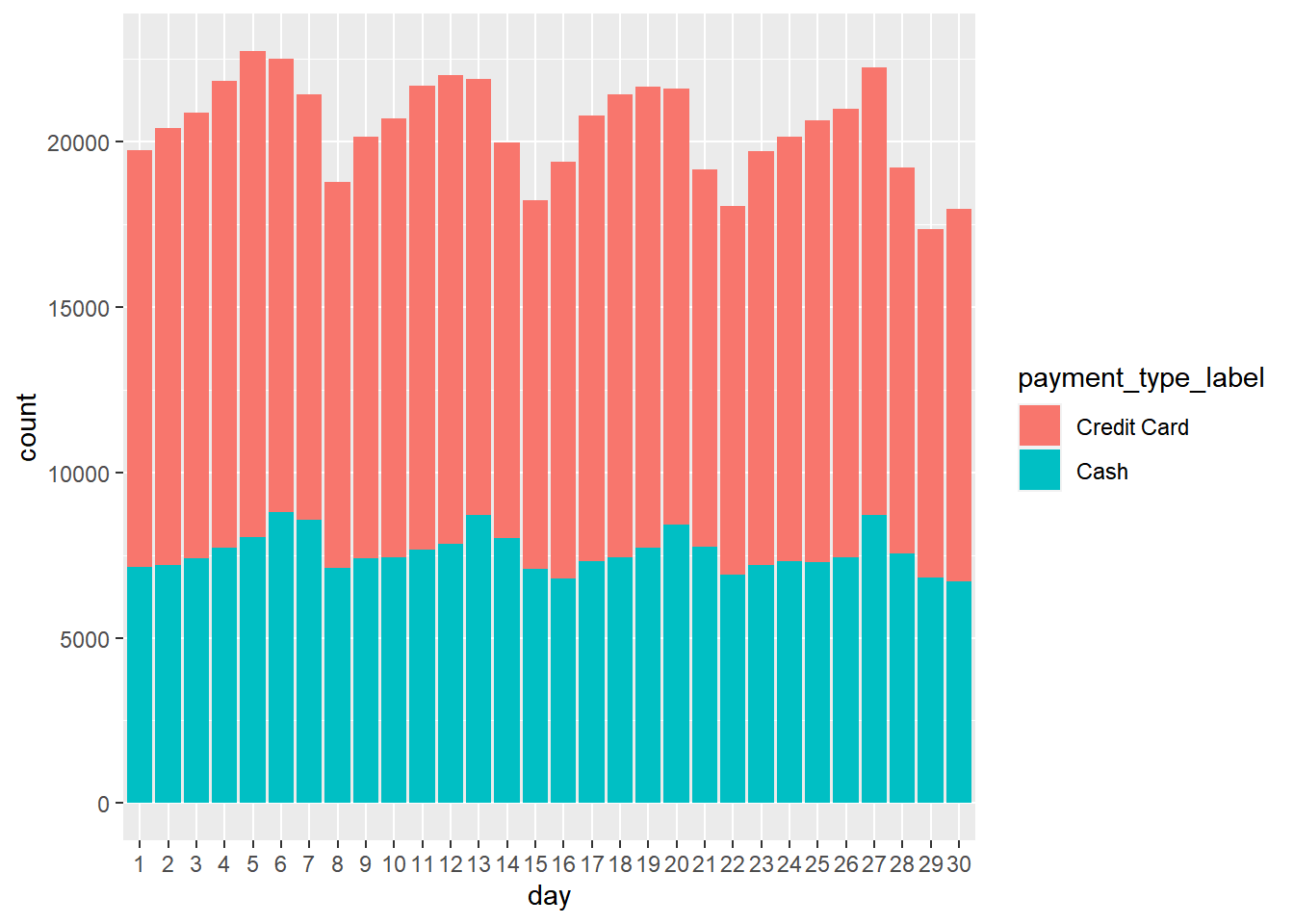
There are clearly more credit card rides than cash rides. If you “dodge” the bars you can plot them next to each other instead
taxi %>%
filter(payment_type_label %in% c('Credit Card','Cash')) %>%
ggplot(aes(x=day,fill=payment_type_label)) + geom_bar(position='dodge')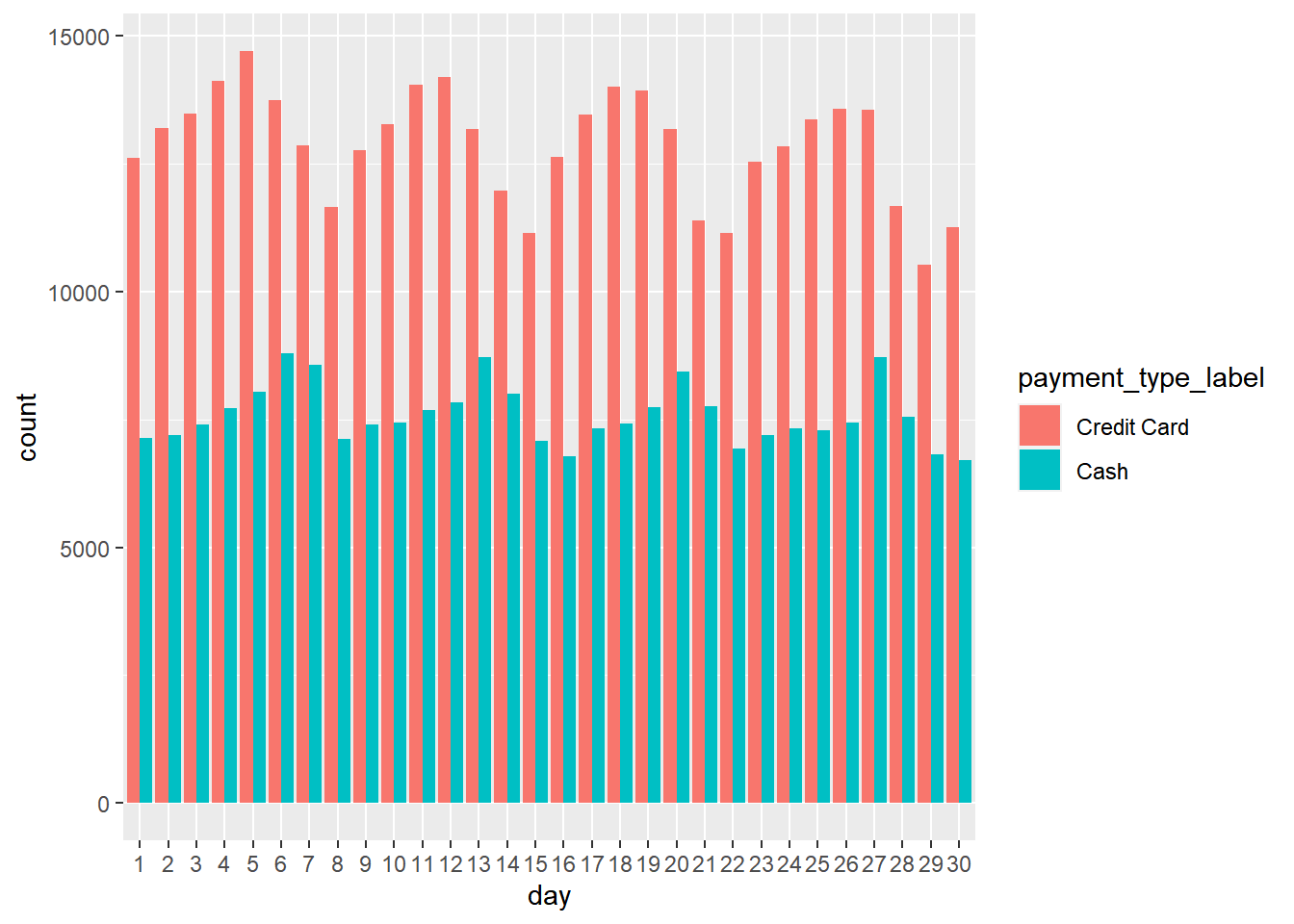
Next, let’s look at ride activity by time of day
taxi %>%
ggplot(aes(x=hour.trip.start)) + geom_bar() 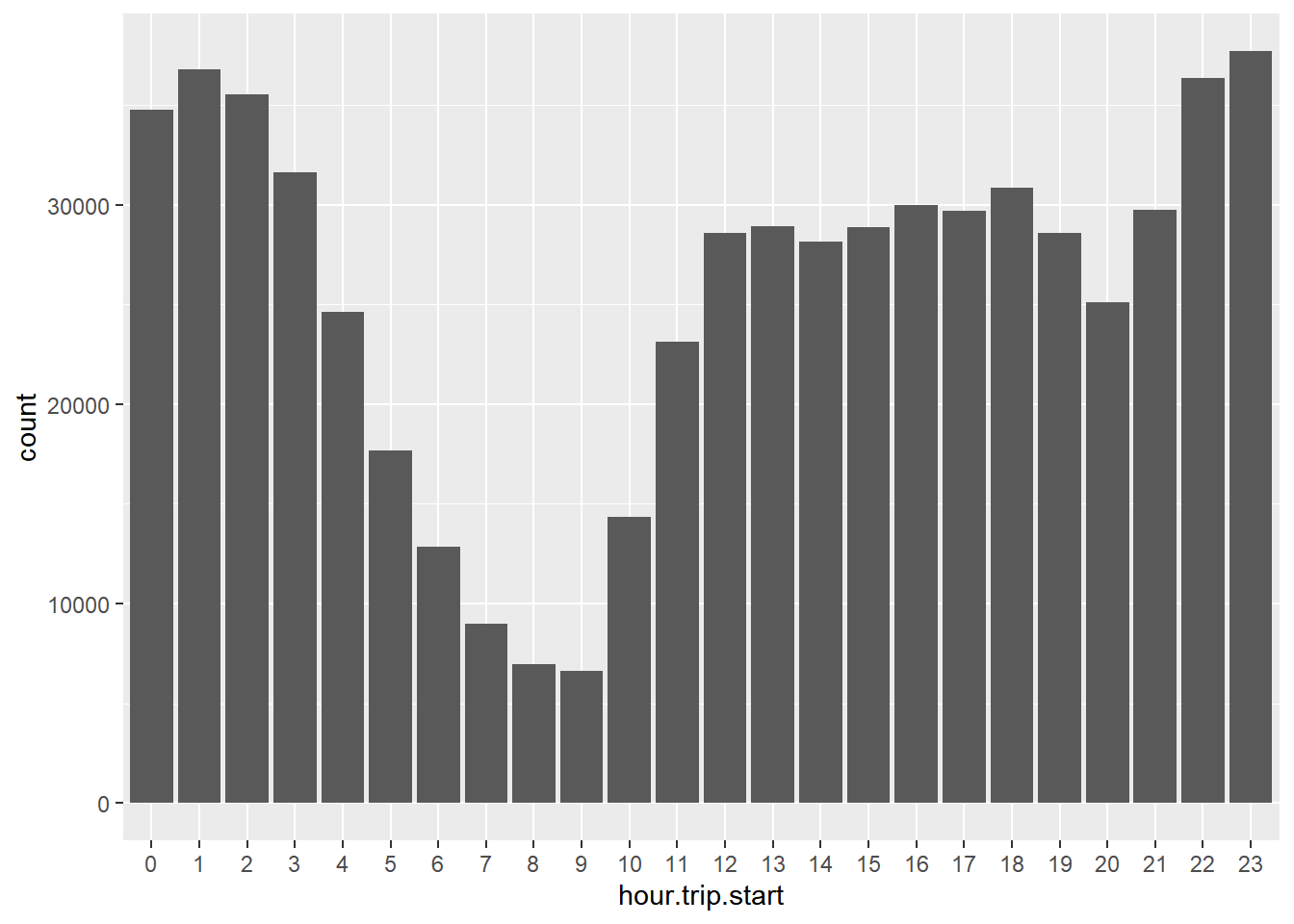
Between 8am and 3pm there is a stable and roughly constant number of rides. Trip demand then increases between 6pm and 10pm. Above we saw that, overall, there were substantially more credit card rides than cash rides. Is this true throughout the day?
taxi %>%
filter(payment_type_label %in% c('Credit Card','Cash')) %>%
ggplot(aes(x=hour.trip.start,fill=payment_type_label)) + geom_bar(position='dodge') 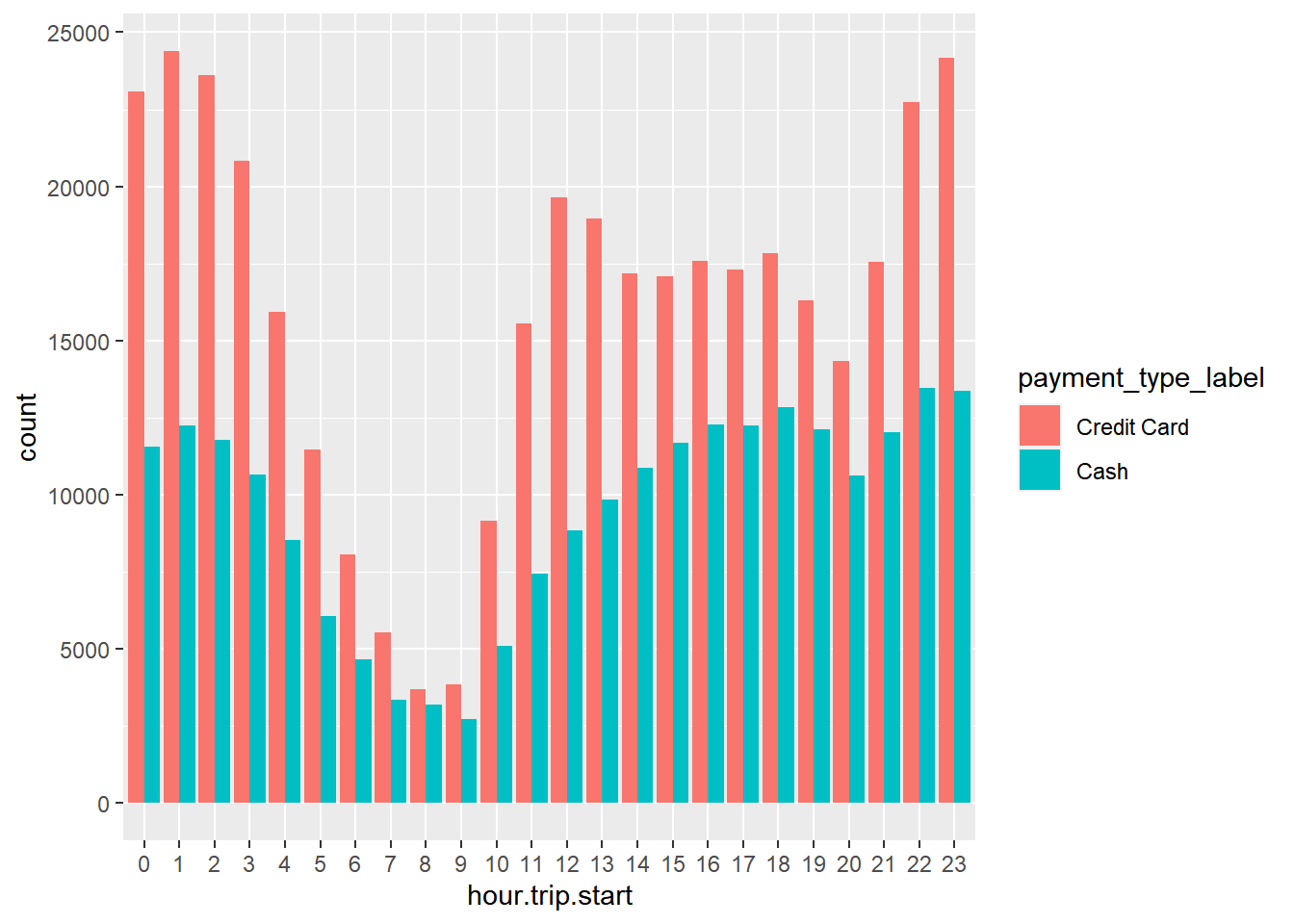
We see a large variation in the ratio of payment types throughout the day. For example, in the evening there are about twice as many credit card trips compared to cash trips. However, in the early morning it is close to 50-50.
Let’s break out trips by day of week
taxi %>%
ggplot(aes(x=weekday)) + geom_bar() 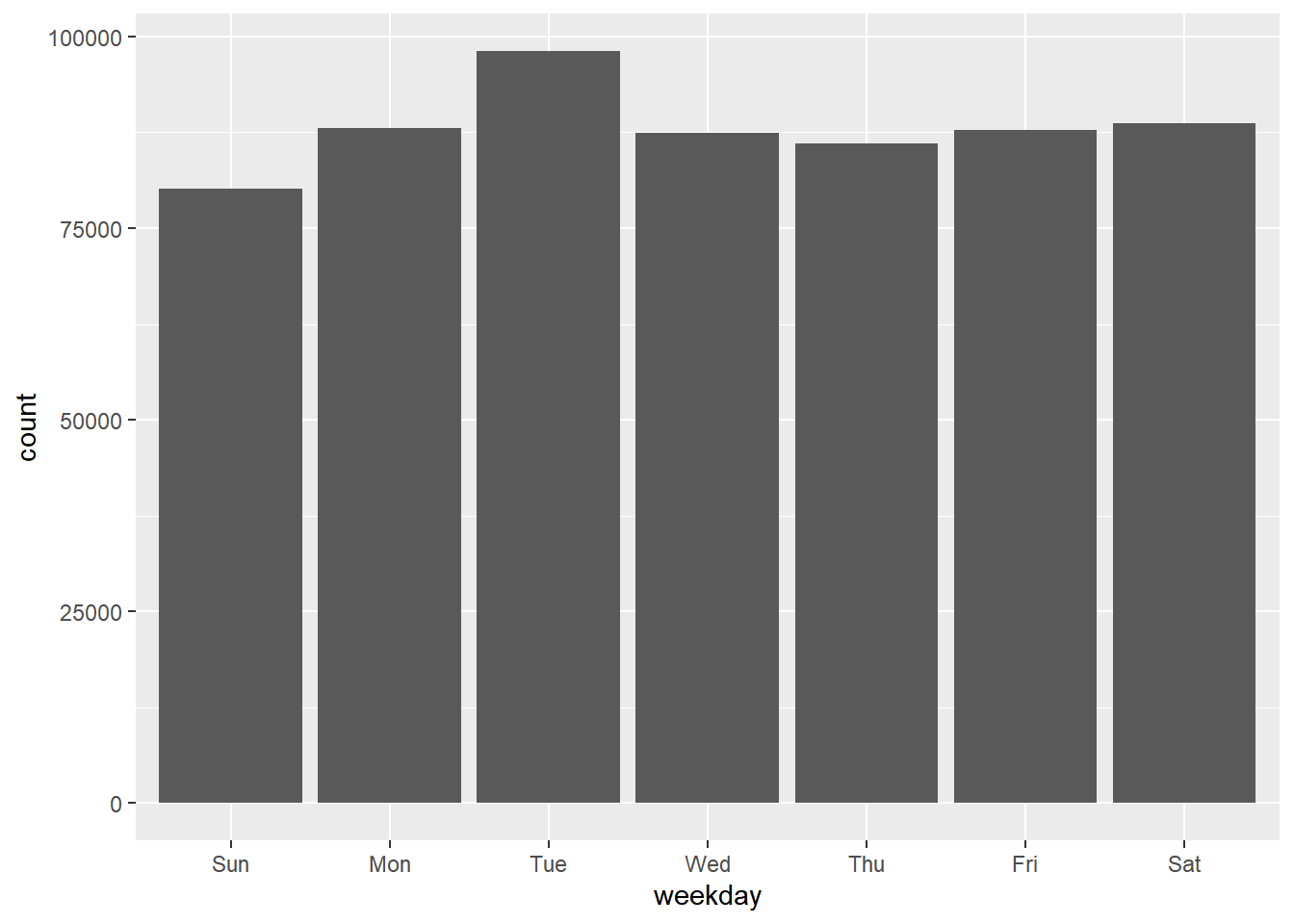
Substantially more trips on Tuesdays? That sounds weird. Here it is important to remember two things: What the structure of the data is and how R plots the data. Remember that the data are all trips for each day of June 2015. To determine the height of a bar, R will count the number of rows for each value of weekday. If your objective is to compare the number of trips for each day of week, this calculation will only make sense if there are the same number of each weekday in a month. Let’s check
taxi %>%
group_by(day) %>%
summarize(weekday=weekday[1]) %>%
count(weekday)# A tibble: 7 x 2
weekday n
<ord> <int>
1 Sun 4
2 Mon 4
3 Tue 5
4 Wed 5
5 Thu 4
6 Fri 4
7 Sat 4So there were 5 Mondays and Tuesdays but only 4 of every other weekday in June 2015. That’s why Mondays and Tuesdays appear to have the most number of rides. To correct this, we can manually calculate the number of rides for each day of the month, while recording what weekday it is. Then we can simply average across weekdays and plot the result. Here is one way of doing this
taxi %>%
group_by(day) %>%
summarize(n = n(),
wday = weekday[1]) %>%
group_by(wday) %>%
summarize(n.trip.mean=mean(n)) %>%
ggplot(aes(x=wday,y=n.trip.mean)) + geom_bar(stat='identity')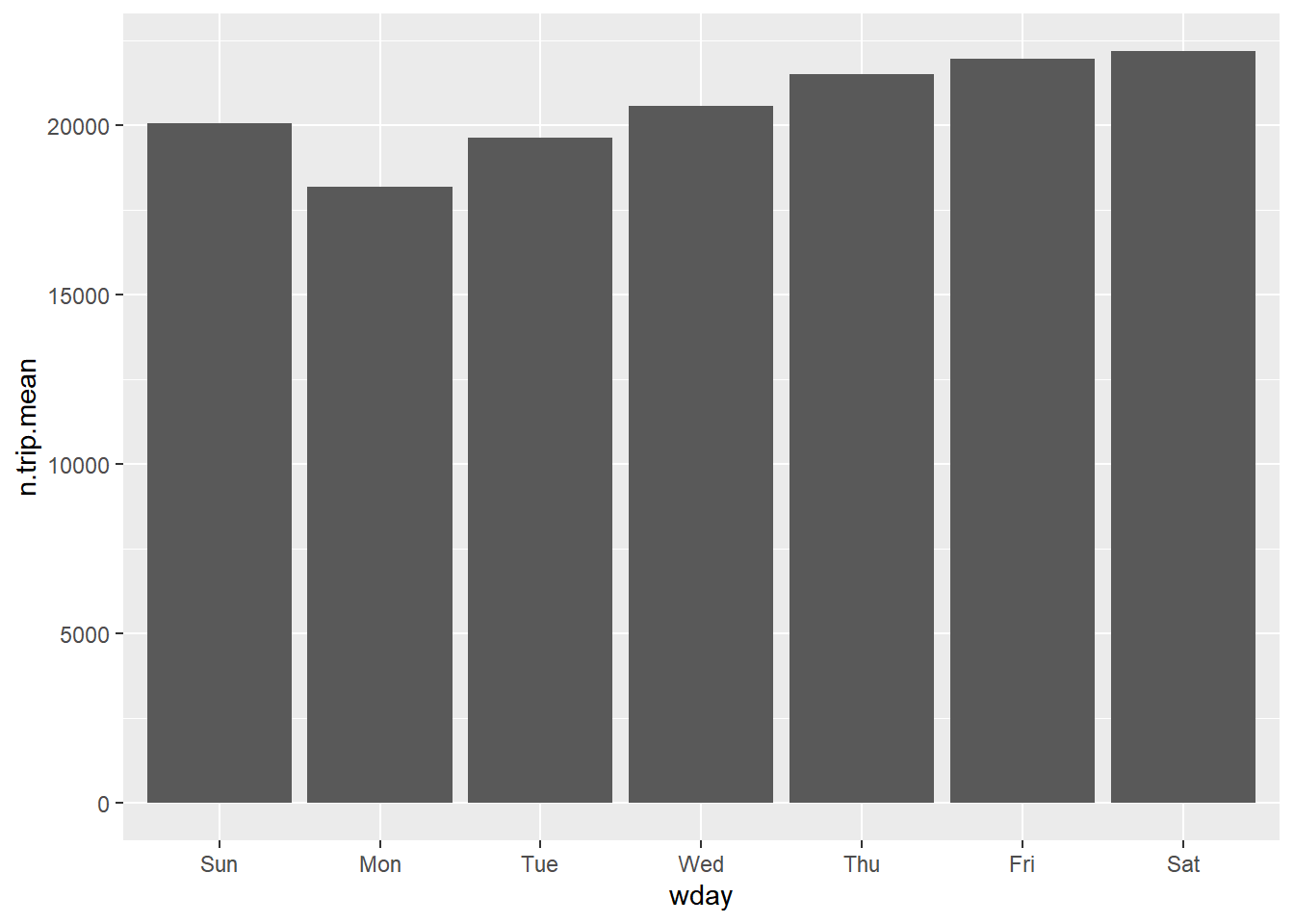
Since you have already calculated the height of each bar, you need to tell R what the variable capturing bar-height is (below “n.trip.mean”) and that no more counting is necessary (stat=‘identity’).
If you don’t like bar charts, you can create point-chart versions of the plots instead. In this case you have to explicitly inform R about what goes on the x and y-axis
taxi %>%
count(day) %>%
ggplot(aes(x=day,y=n)) + geom_point() 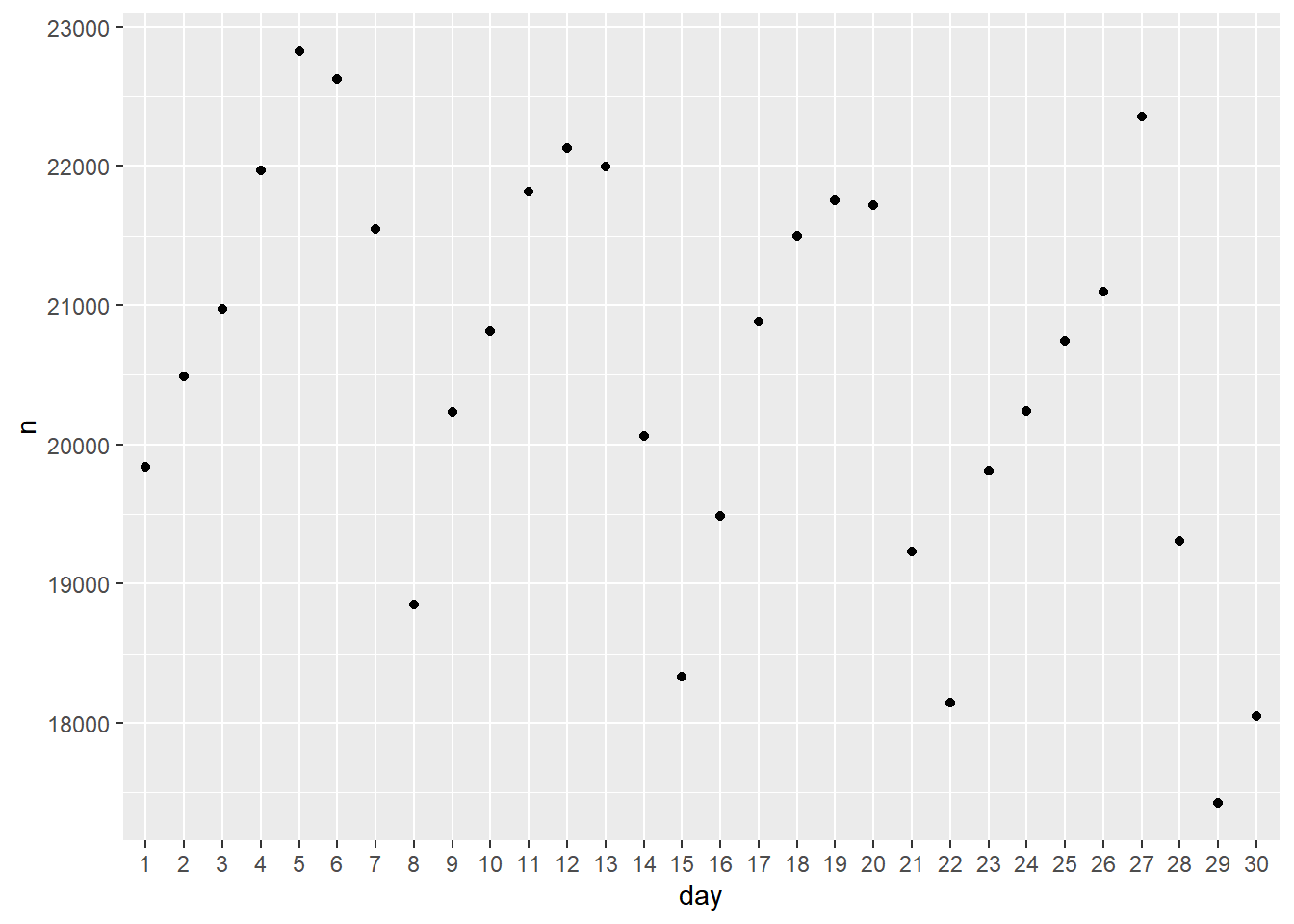
Here it might be good to connect the points by a line to indicate the time-series nature of the data
taxi %>%
count(day) %>%
ggplot(aes(x=day,y=n)) + geom_point() + geom_line(aes(group=1),linetype='dotted')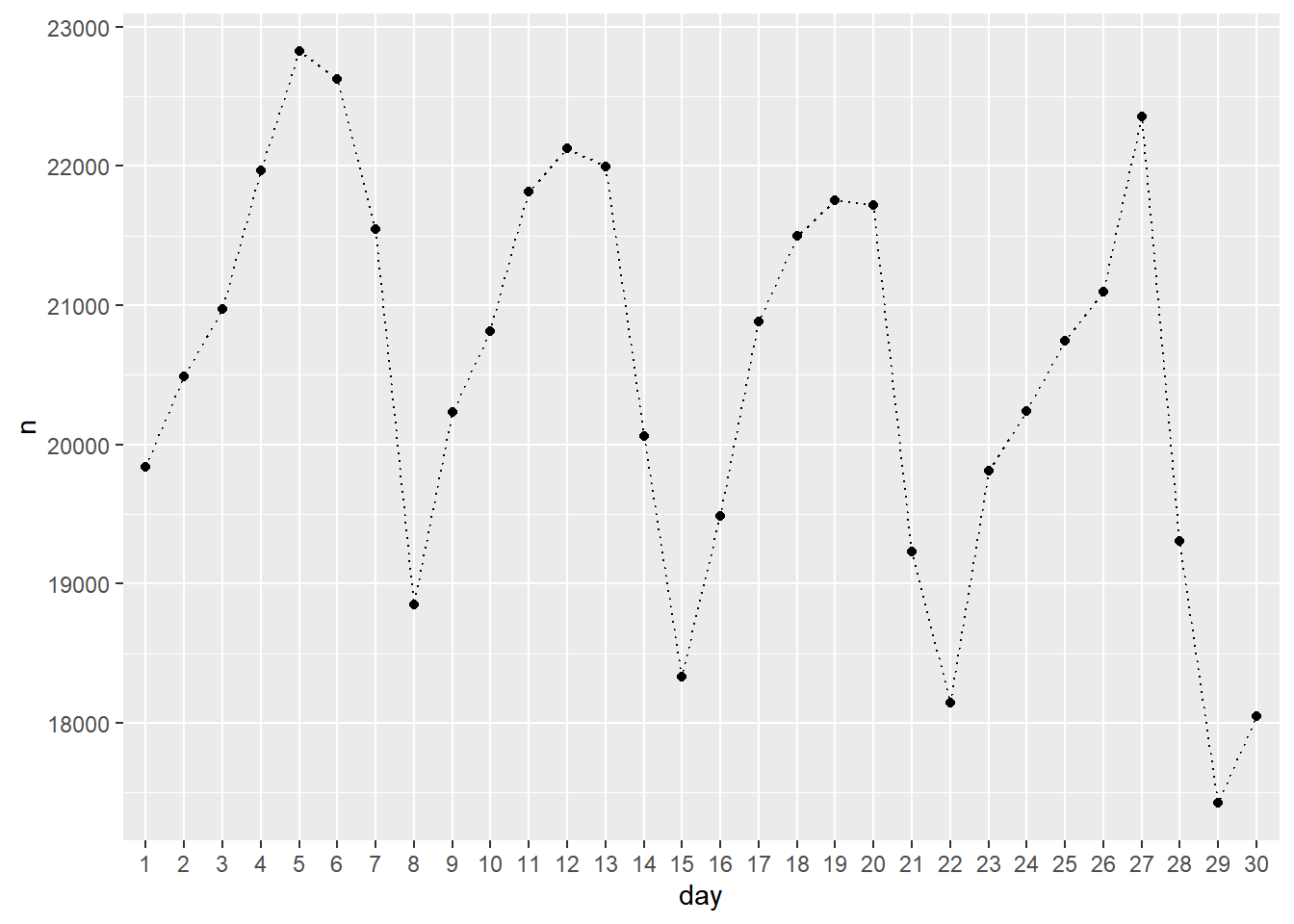
You need to tell R which points to connect. The option group=1 simply means all of them. Here is the time of day version using points and lines
taxi %>%
count(hour.trip.start) %>%
ggplot(aes(x=hour.trip.start,y=n)) +
geom_point() +
geom_line(aes(group=1),linetype='dotted')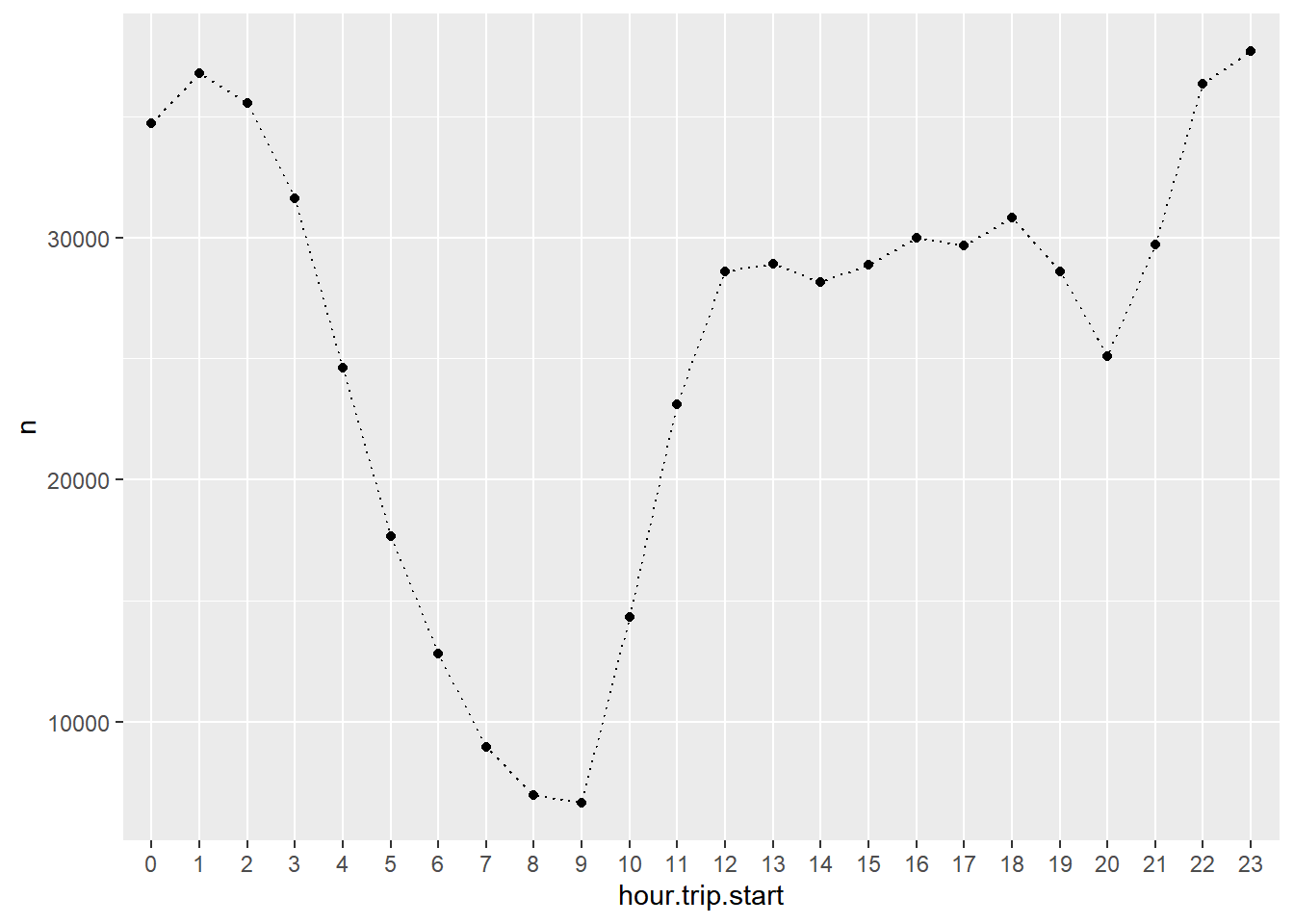
Let’s add payment type using a different color for each payment
taxi %>%
filter(payment_type_label %in% c('Credit Card','Cash')) %>%
count(payment_type_label, hour.trip.start) %>%
ggplot(aes(x=hour.trip.start,y=n,color=payment_type_label,group=payment_type_label)) +
geom_point() +
geom_line(linetype='dotted')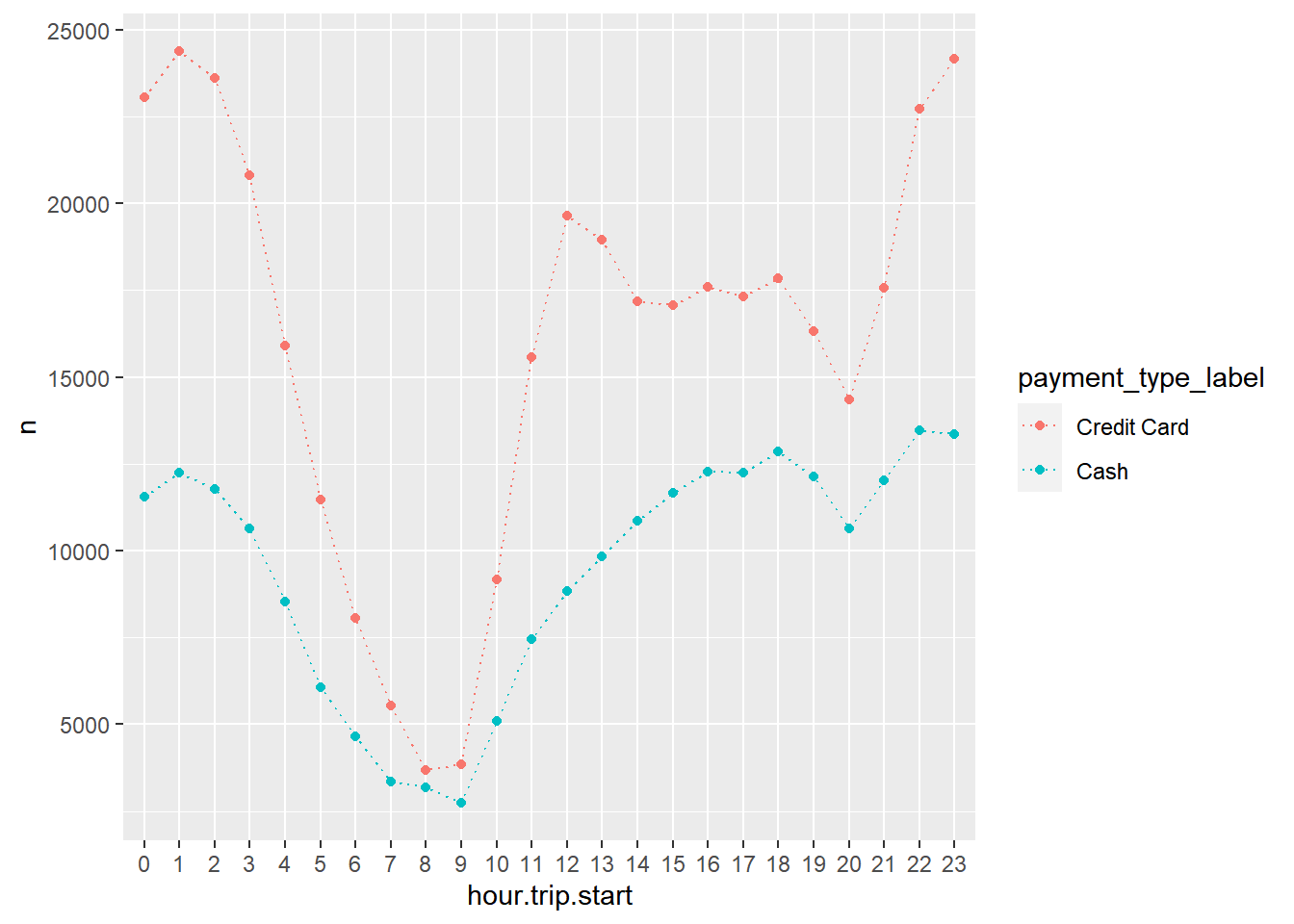
Trip Duration
Let’s now turn to visualizing the duration of trips. What is the overall distribution of trip durations? We can use a histogram
taxi %>%
ggplot(aes(x=trip.duration)) + geom_histogram()`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.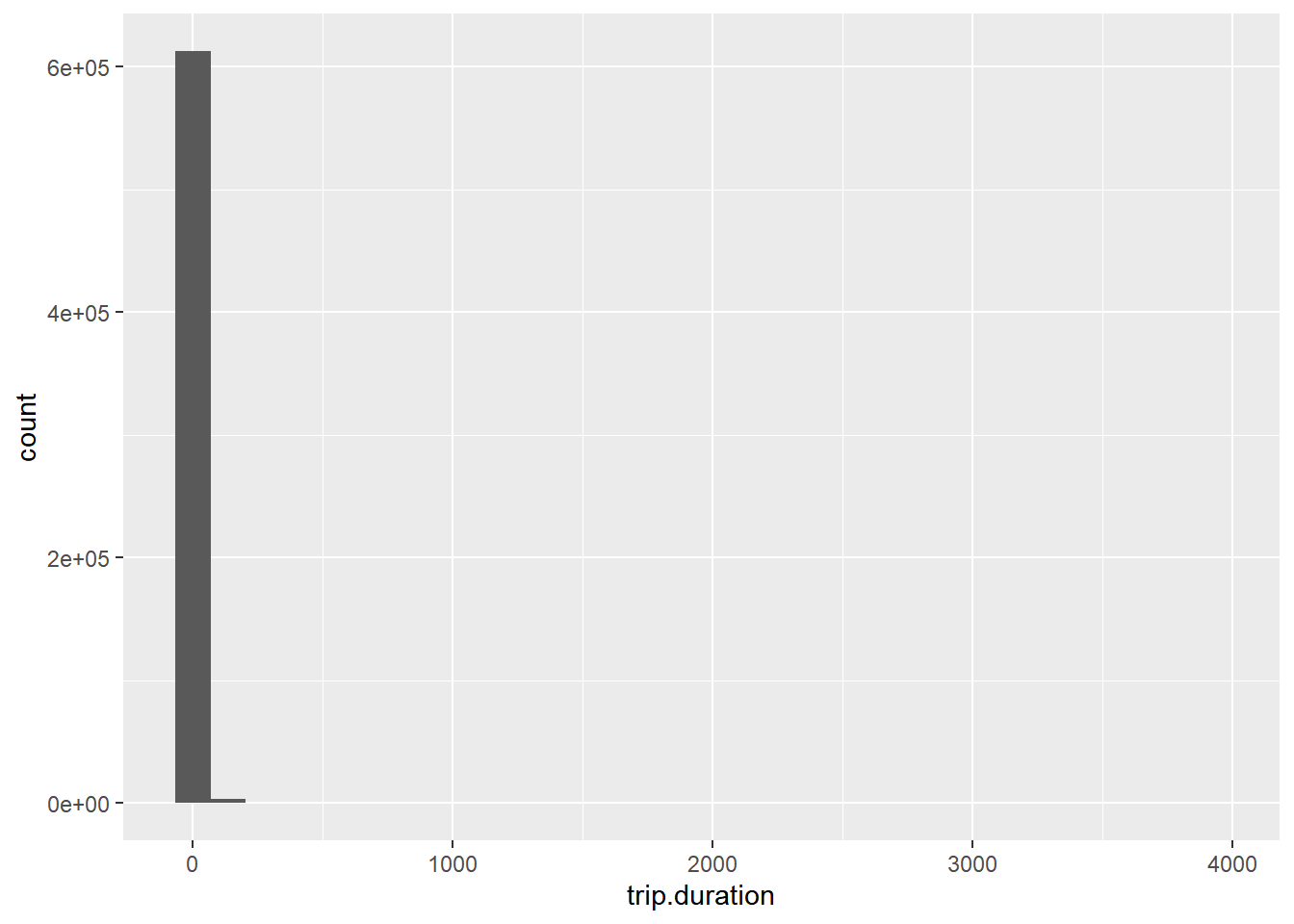
ehh….what?? - that’s a weird histogram. This is the (very standard) problem of outliers. Here are the 5 longest trips in the data
taxi %>%
arrange(desc(trip.duration)) %>%
select(tpep_pickup_datetime,tpep_dropoff_datetime,trip.duration) %>%
slice(1:5)# A tibble: 5 x 3
tpep_pickup_datetime tpep_dropoff_datetime trip.duration
<dttm> <dttm> <dbl>
1 2015-06-27 21:42:24 2015-06-30 14:53:08 3911.
2 2015-06-19 02:37:26 2015-06-20 02:37:02 1440.
3 2015-06-07 22:40:43 2015-06-08 22:40:08 1439.
4 2015-06-28 03:47:54 2015-06-29 03:47:16 1439.
5 2015-06-10 01:45:47 2015-06-11 01:45:09 1439.Alright - those are some long trips! Recall that this is measured in minutes. Is this normal? What percentage of rides are above 2 hours?
sum(taxi$trip.duration > 120)/nrow(taxi)[1] 0.0009330674Only 0.09% of trips are longer than 2 hours. So let’s cut off the histogram at 2 hours
taxi %>%
ggplot(aes(x=trip.duration)) + geom_histogram() + xlim(0,120)`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 578 rows containing non-finite values (`stat_bin()`).Warning: Removed 2 rows containing missing values (`geom_bar()`).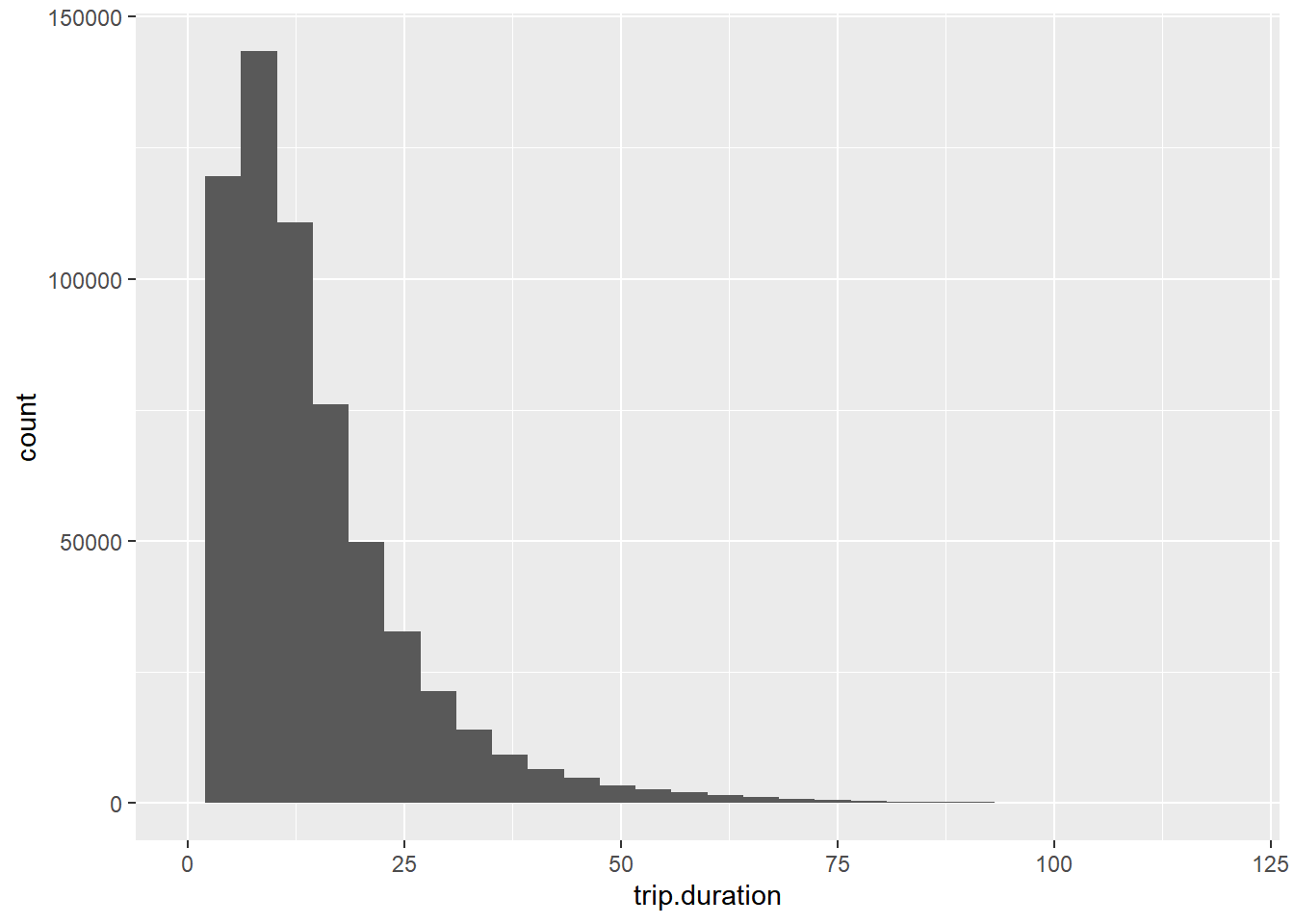
Much better! Most trips are less than 60 minutes with the vast majority of trips between 0 and 25 minutes. This is also a highly skewed distribution so if we want to characterize the “typical” trip duration we should probably not use the average. In the following we will focus on the median trip duration.
Here is the median duration for each day of the month
taxi %>%
group_by(day) %>%
summarize(med.duration=median(trip.duration)) %>%
ggplot(aes(x=day,y=med.duration)) +
geom_point() +
geom_line(aes(group=1),linetype='dotted')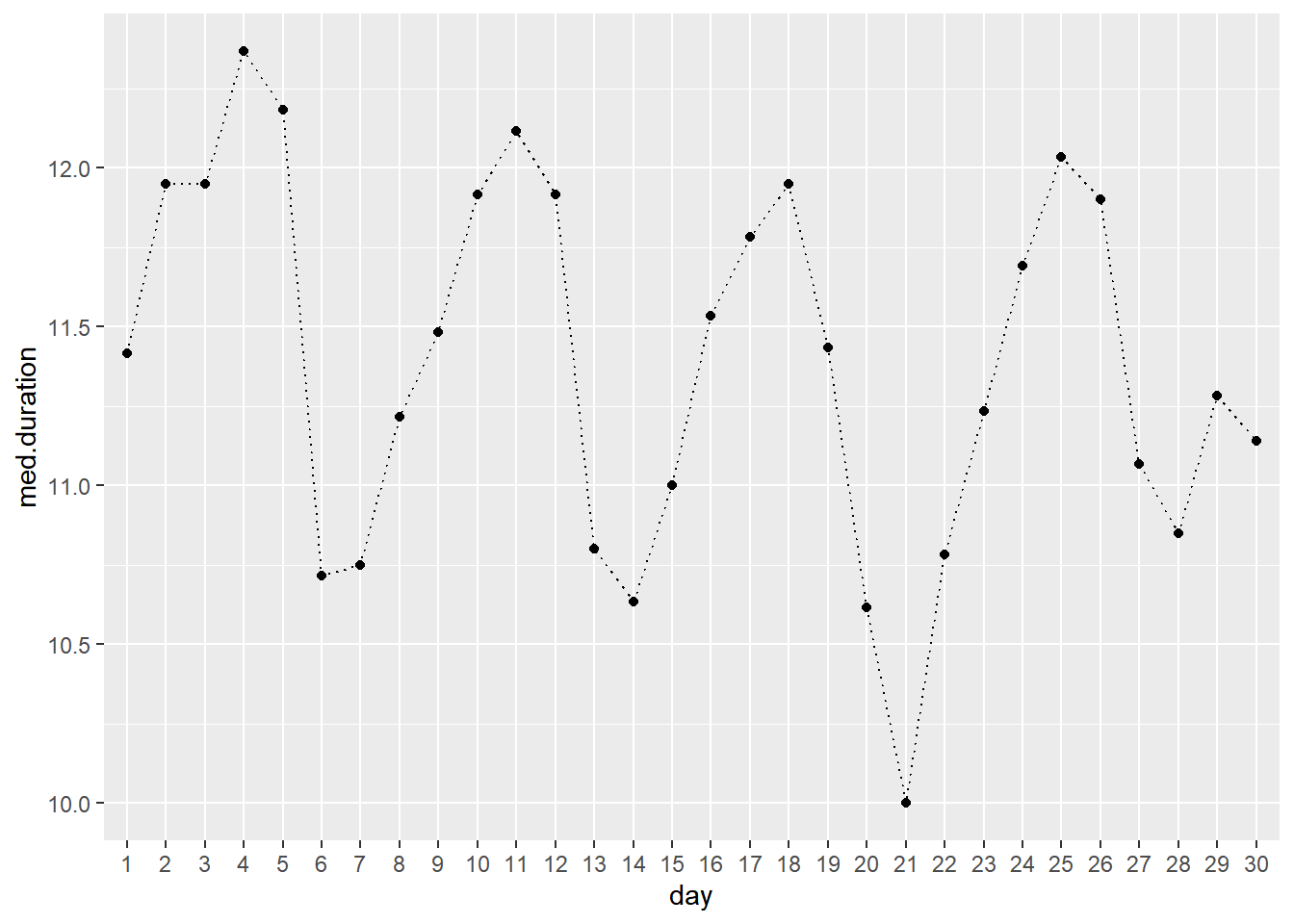
Let’s “pretty-up” this plot a bit by adding some axis titles and weekday information
taxi %>%
group_by(day) %>%
summarize(med.duration=median(trip.duration),
weekday=weekday[1]) %>%
ggplot(aes(x=day,y=med.duration,group=1)) +
geom_point(aes(color=weekday),size=5) +
geom_line(linetype='dotted')+
labs(x='Day of Month',
y='Median Trip Duration (Mins.)',
title='Median Trip Duration by Day of Month')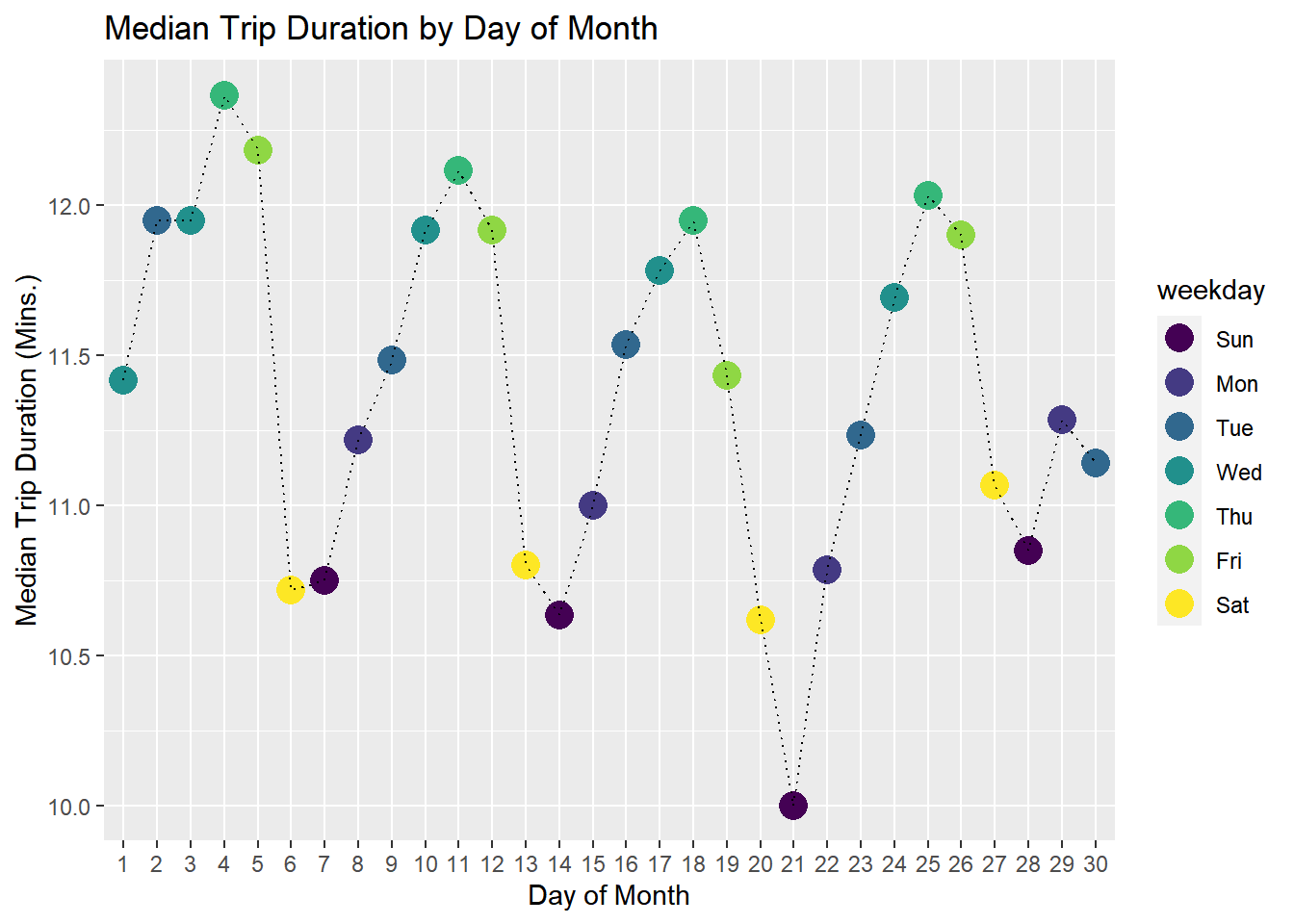
In terms of duration, the longest trips happen mid-week, while the shortest are on weekends. An alternative approach is to add labels directly on the plot
taxi %>%
group_by(day) %>%
summarize(med.duration=median(trip.duration),
weekday=weekday[1]) %>%
ggplot(aes(x=day,y=med.duration)) + geom_text(aes(label=weekday)) +
geom_line(aes(group=1),linetype='dotted')+
labs(x='Day of Month',
y='Median Trip Duration (Mins.)',
title='Median Trip Duration by Day of Month')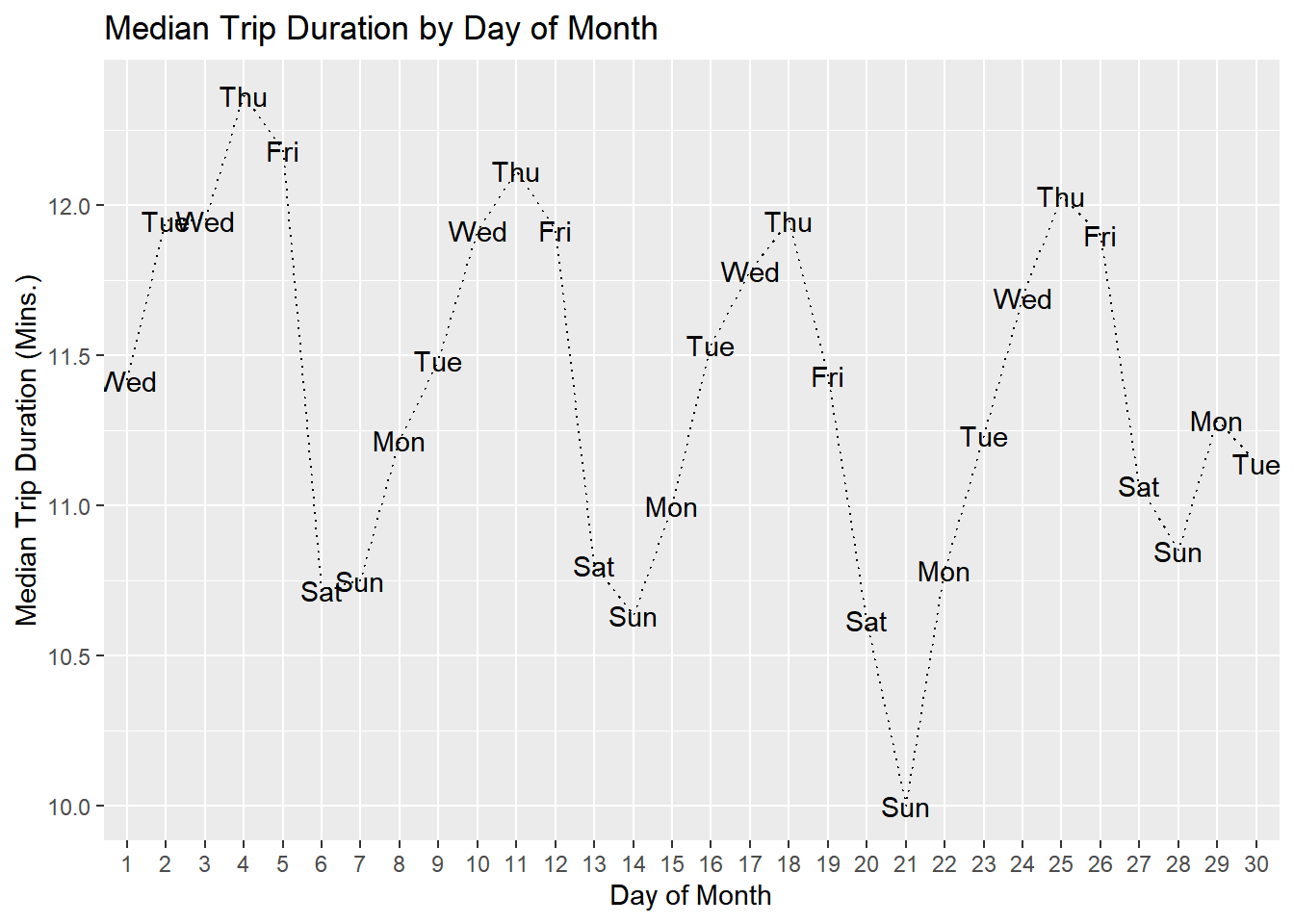
Now let’s look at median trip duration by time of day
taxi %>%
group_by(hour.trip.start) %>%
summarize(med.duration=median(trip.duration)) %>%
ggplot(aes(x=hour.trip.start,y=med.duration)) +
geom_point() +
geom_line(aes(group=1),linetype='dotted')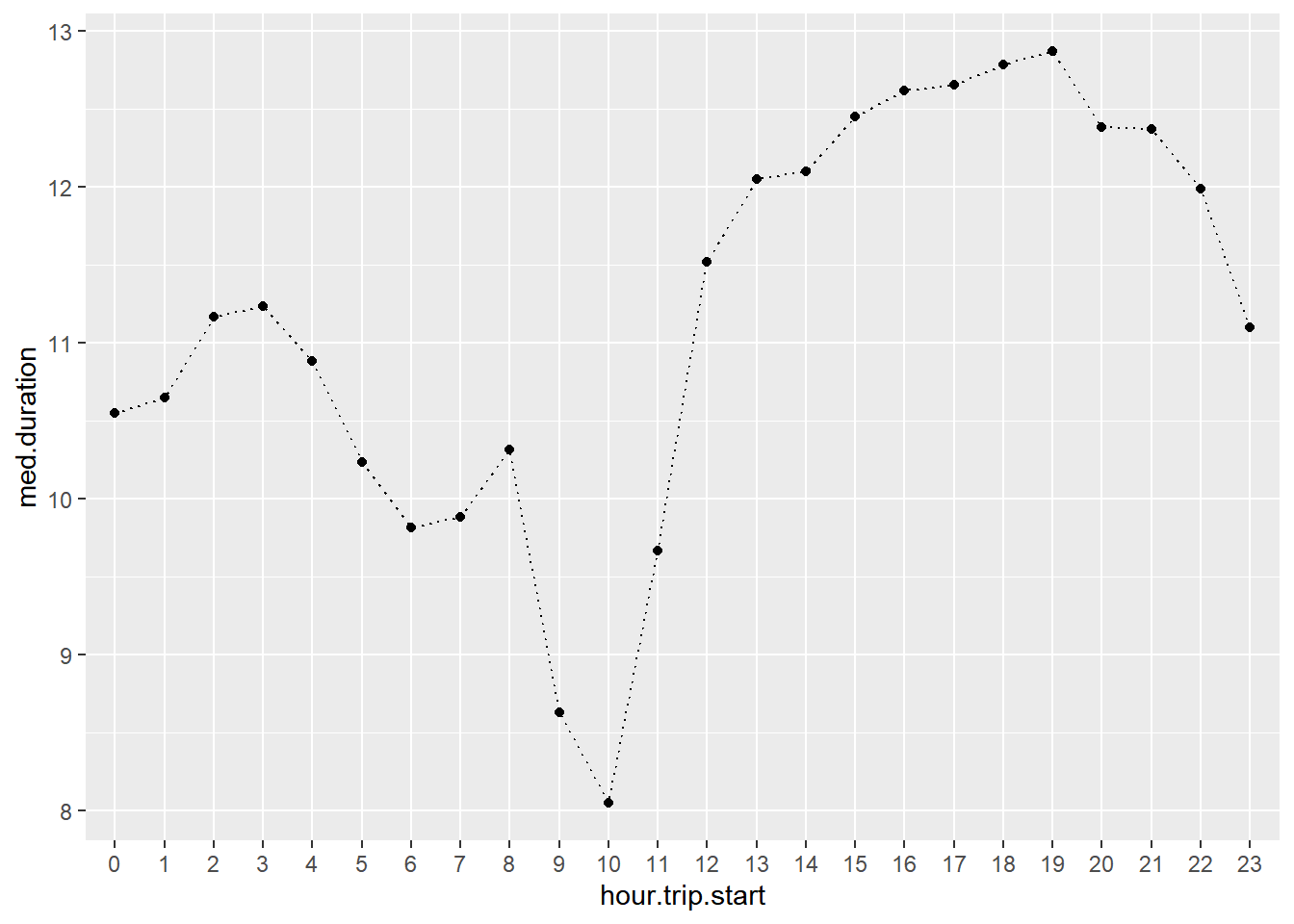
Does this pattern stay stable throughout the week? Let’s break out this relationship for each weekday
taxi %>%
group_by(weekday,hour.trip.start) %>%
summarize(med.duration=median(trip.duration)) %>%
ggplot(aes(x=hour.trip.start,y=med.duration,group=weekday,color=weekday)) +
geom_point(size=3) +
geom_line(size=0.5) +
facet_wrap(~weekday,nrow=1) +
theme(legend.position="none")+
scale_x_discrete(breaks=c(0,3,6,9,12,15,18,21))`summarise()` has grouped output by 'weekday'. You can override using the
`.groups` argument.Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
i Please use `linewidth` instead.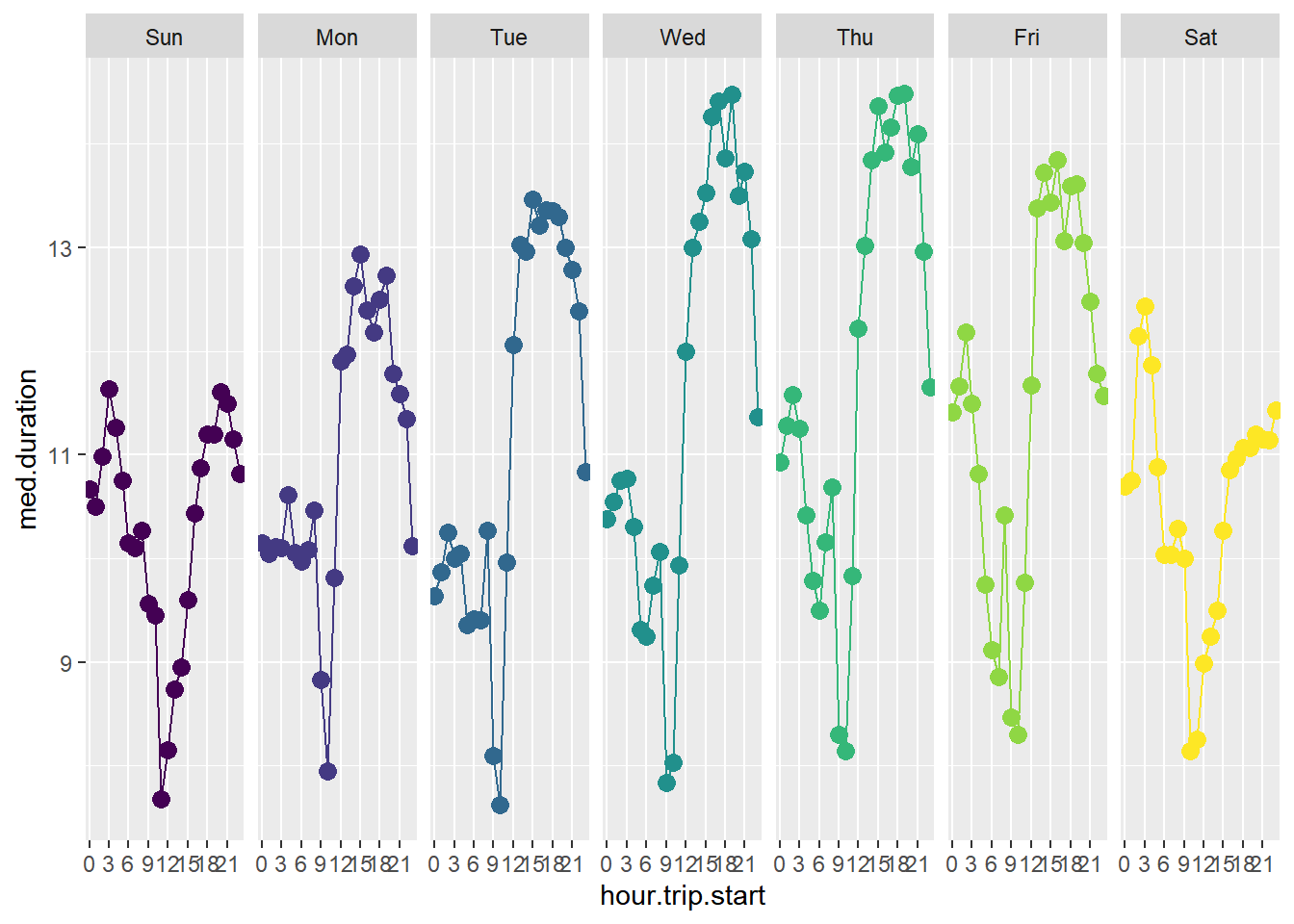
This visualization is an example of a “facet” and this feature alone makes it worthwhile to learn ggplot. A facet repeats the same base plot for every value of the facet variable - here weekday. This makes it laughably easy to make complex and highly informative plots.
You can even create two-dimensional facets. Suppose we wanted to repeat the above plot for each payment type. Easy
taxi %>%
filter(payment_type_label %in% c('Credit Card','Cash')) %>%
group_by(weekday,hour.trip.start,payment_type_label) %>%
summarize(med.duration=median(trip.duration)) %>%
ggplot(aes(x=hour.trip.start,y=med.duration,group=weekday,color=weekday)) +
geom_point(size=3) +
geom_line(size=0.5) +
facet_grid(weekday~payment_type_label) +
theme(legend.position="none")+
scale_x_discrete(breaks=c(0,3,6,9,12,15,18,21))`summarise()` has grouped output by 'weekday', 'hour.trip.start'. You can
override using the `.groups` argument.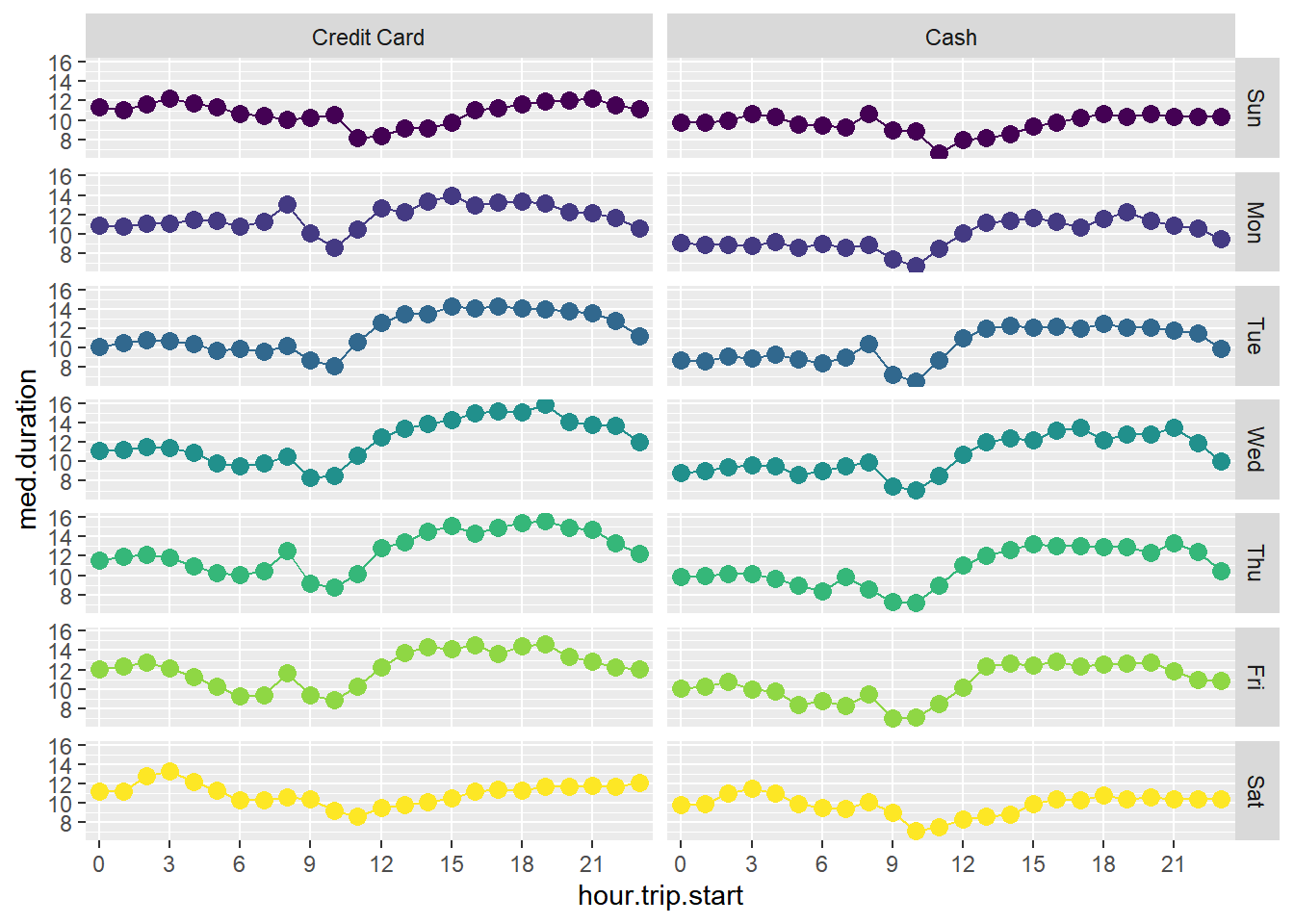
Admittedly this is not a good visualization if the objective is to highlight differences between payment types by weekday and time of day. Here is a better version for that purpose
taxi %>%
filter(payment_type_label %in% c('Credit Card','Cash')) %>%
group_by(weekday,hour.trip.start,payment_type_label) %>%
summarize(med.duration=median(trip.duration)) %>%
ggplot(aes(x=hour.trip.start,y=med.duration,group=payment_type_label,
color=payment_type_label,linetype=payment_type_label,shape=payment_type_label)) +
geom_point(size=2) +
geom_line(size=0.5) +
facet_wrap(~weekday,nrow=1) +
labs(x='Time of Day',
y='Median Trip Duration')+
scale_x_discrete(breaks=c(0,6,12,18))`summarise()` has grouped output by 'weekday', 'hour.trip.start'. You can
override using the `.groups` argument.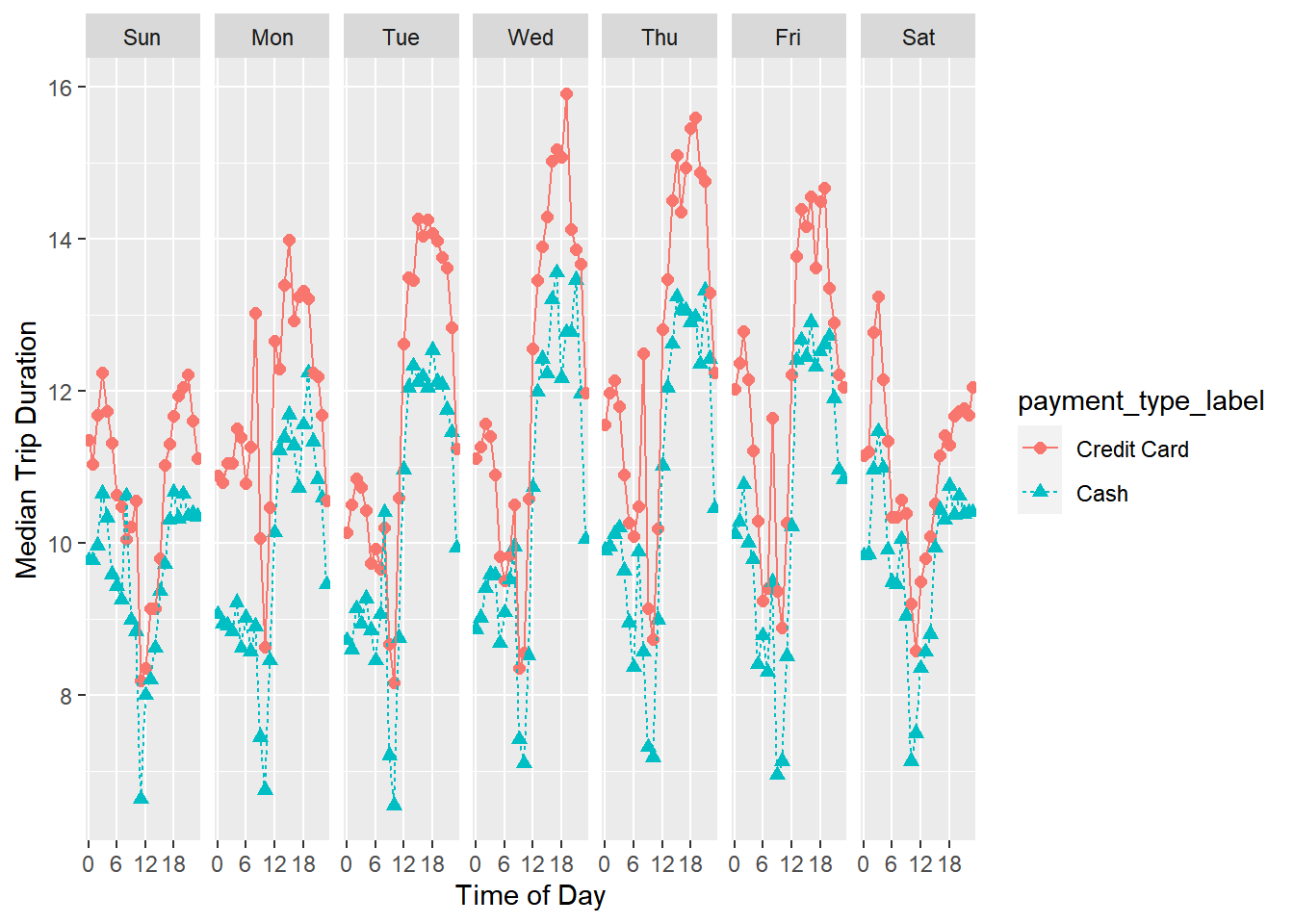
Trips paid with credit card tend to be slightly longer in duration - especially for mid-day and mid-week trips.
Trip Distance Here is median trip distance for each day of the month
taxi %>%
group_by(day) %>%
summarize(med.trip=median(trip_distance),
weekday=weekday[1]) %>%
ggplot(aes(x=day,y=med.trip)) + geom_point(aes(color=weekday),size=5) +
geom_line(aes(group=1),linetype='dotted')+
labs(x = 'Day of Month',
y = 'Median Trip Distance (Miles)',
title = 'Median Trip Distance by Day of Month')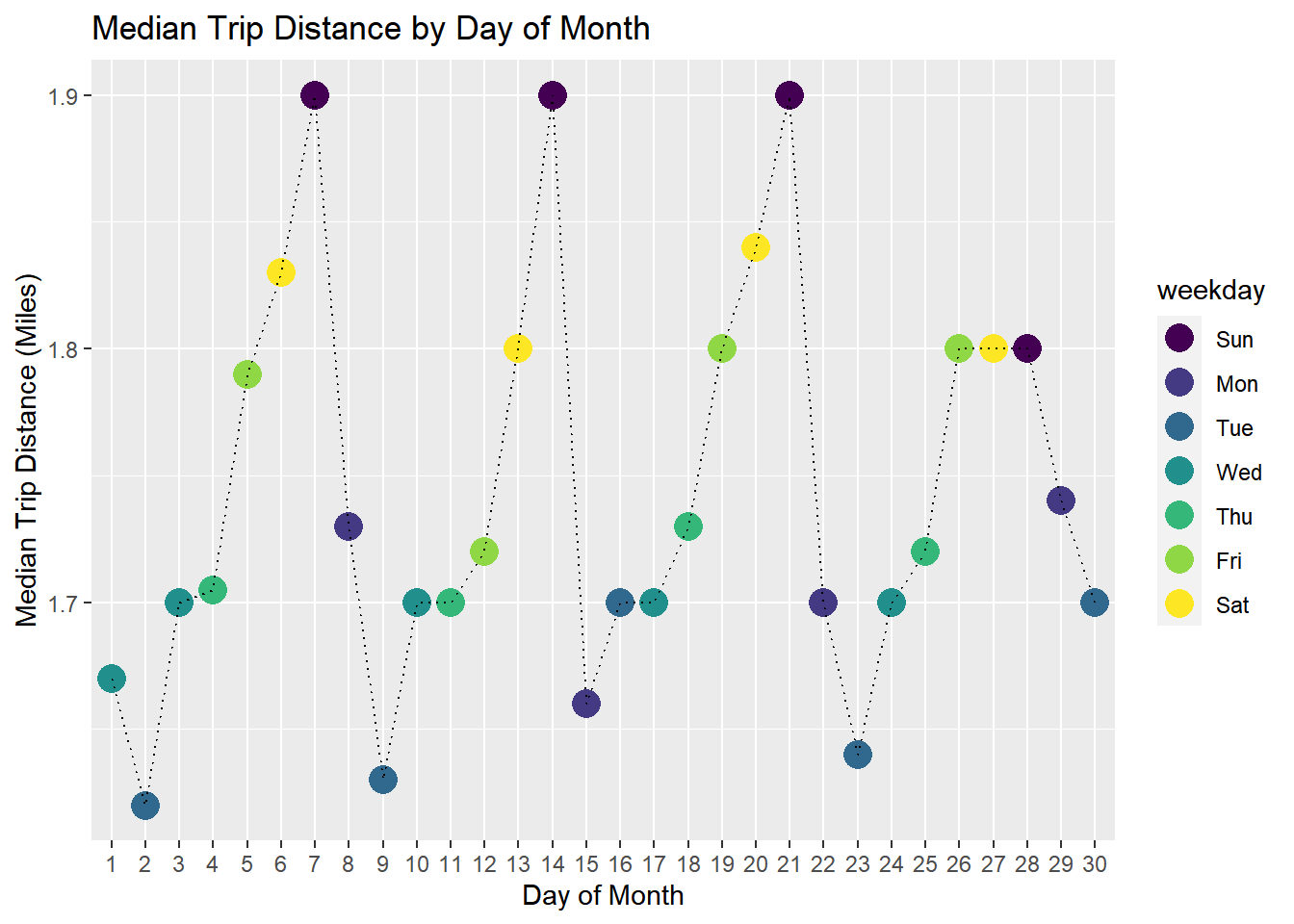
In terms of distance, we see the longest trips on weekends. For time of day we get
taxi %>%
group_by(hour.trip.start) %>%
summarize(med.trip=median(trip_distance)) %>%
ggplot(aes(x=hour.trip.start,y=med.trip)) +
geom_point(size=3) +
geom_line(aes(group=1),linetype='dotted')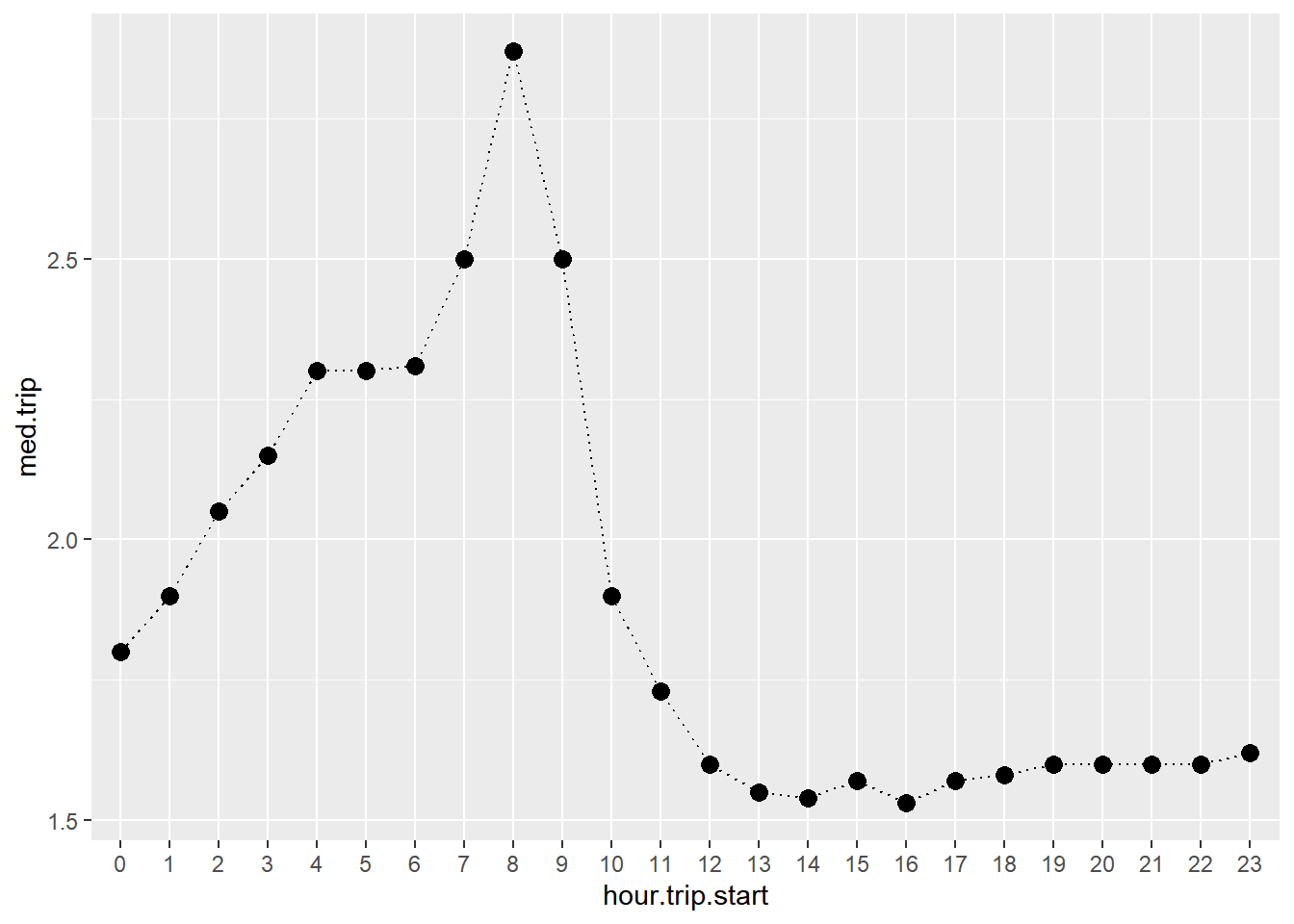
Trips are longer at night and shortest during the day. Here is the version where we cut it by weekday
taxi %>%
group_by(weekday,hour.trip.start) %>%
summarize(med.trip=median(trip_distance)) %>%
ggplot(aes(x=hour.trip.start,y=med.trip,group=weekday,color=weekday)) +
geom_point(size=3) +
geom_line(size=0.5) +
facet_wrap(~weekday,nrow=1) +
theme(legend.position="none")+
scale_x_discrete(breaks=c(0,3,6,9,12,15,18,21))`summarise()` has grouped output by 'weekday'. You can override using the
`.groups` argument.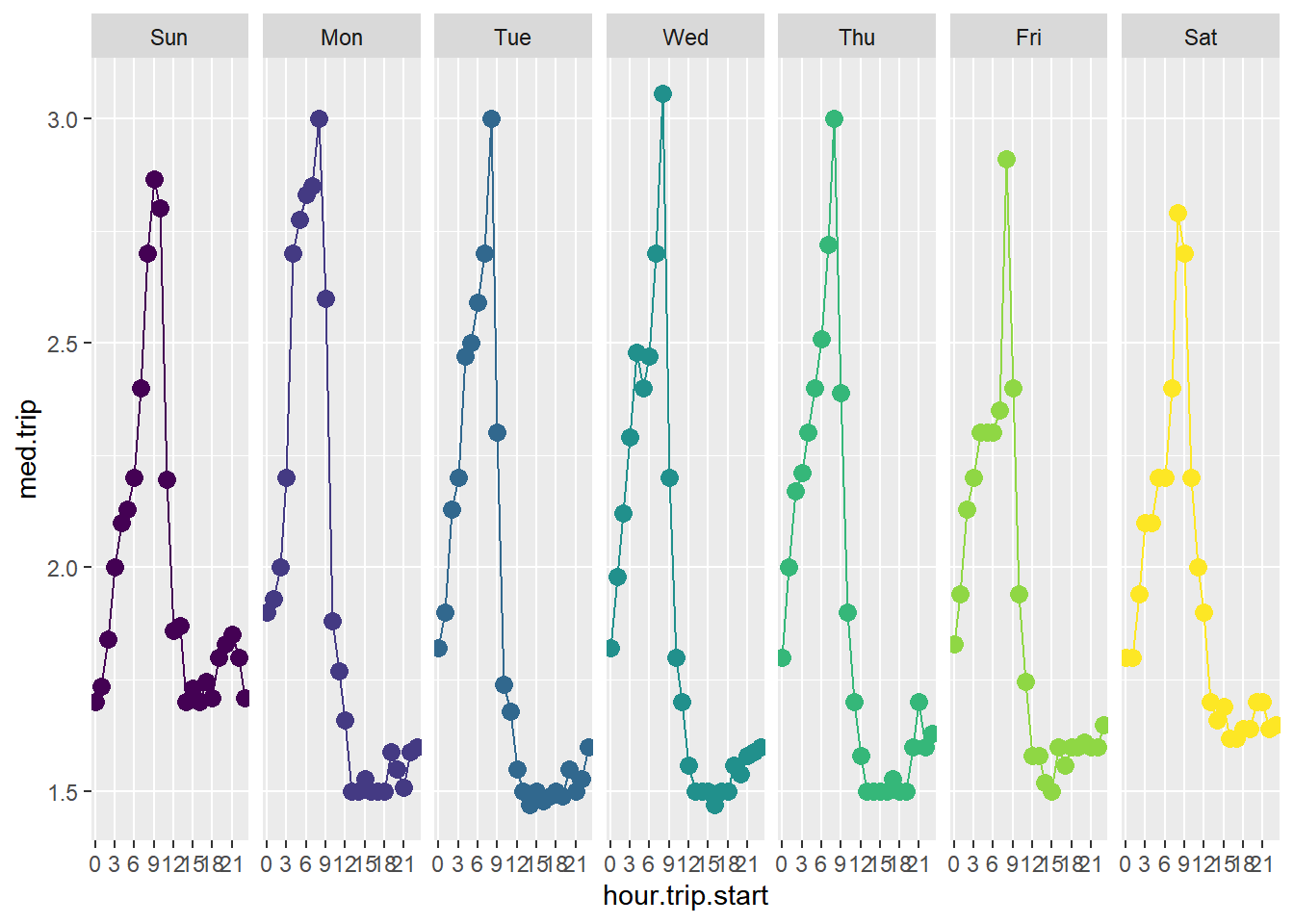
Taxi Exercise 1: Trip Speed Try to visualize trip speed and distance across time of day and day of week. Do you see any interesting patterns? Do your findings make sense when compared to the findings for trip duration and distance?
Fares Let’s look are fare mounts for each payment type:
taxi %>%
filter(payment_type_label %in% c('Credit Card','Cash')) %>%
ggplot(aes(x=fare_amount,fill=payment_type_label)) + geom_histogram() + facet_wrap(~payment_type_label) + xlim(0,75)+
theme(legend.position="none")`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 914 rows containing non-finite values (`stat_bin()`).Warning: Removed 4 rows containing missing values (`geom_bar()`).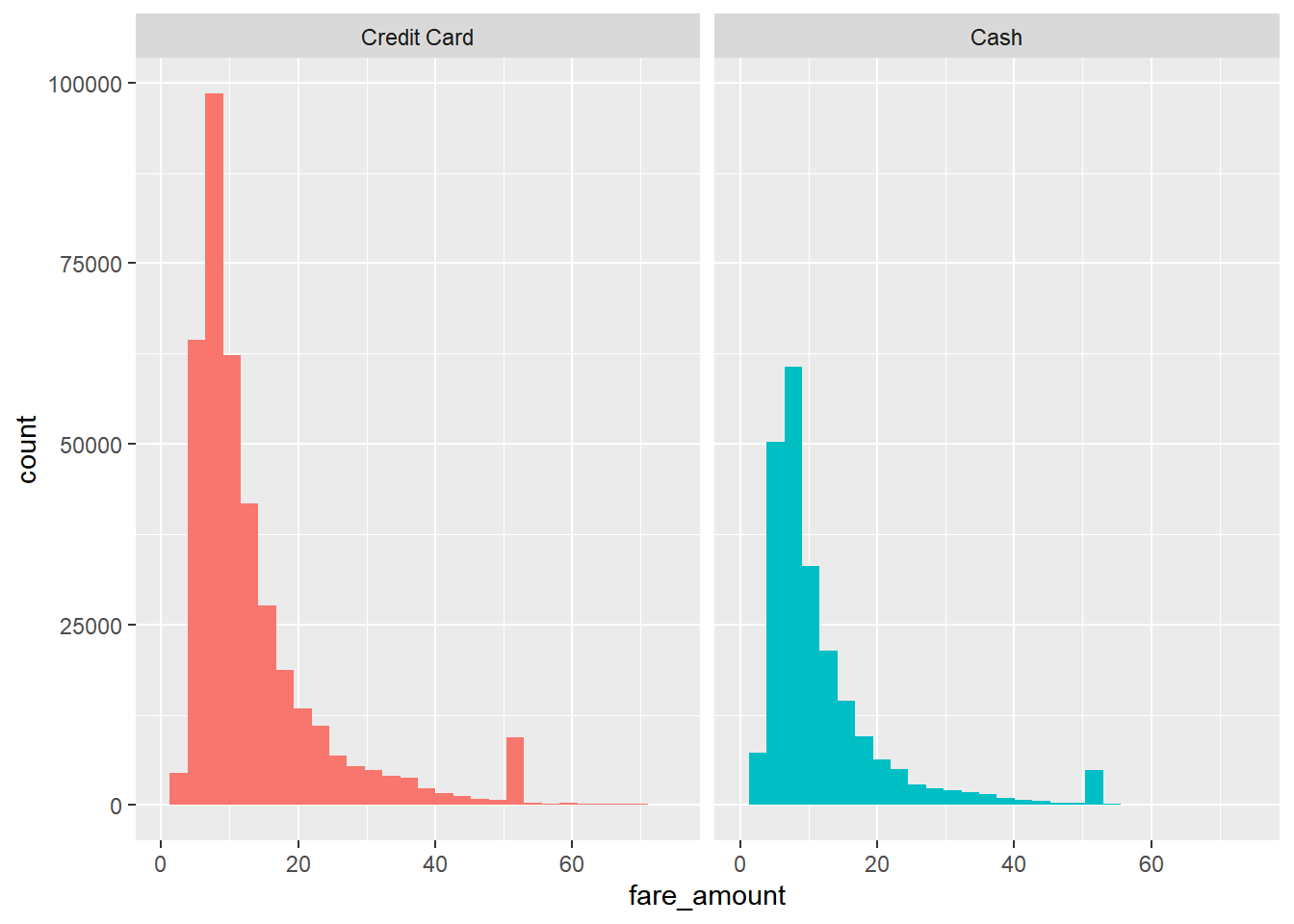
These distributions are not too different - credit card trips appear to have slightly larger fares.
How fares by day of week?
taxi %>%
filter(fare_amount < 100) %>%
group_by(day) %>%
summarize(mean.fare=mean(fare_amount),
weekday=weekday[1]) %>%
ggplot(aes(x=day,y=mean.fare)) + geom_point(aes(color=weekday),size=5) +
geom_line(aes(group=1),linetype='dotted')+
labs(x = 'Day of Month',
y = 'Mean Fare ($)',
title = 'Mean Fare Amount by Day of Month')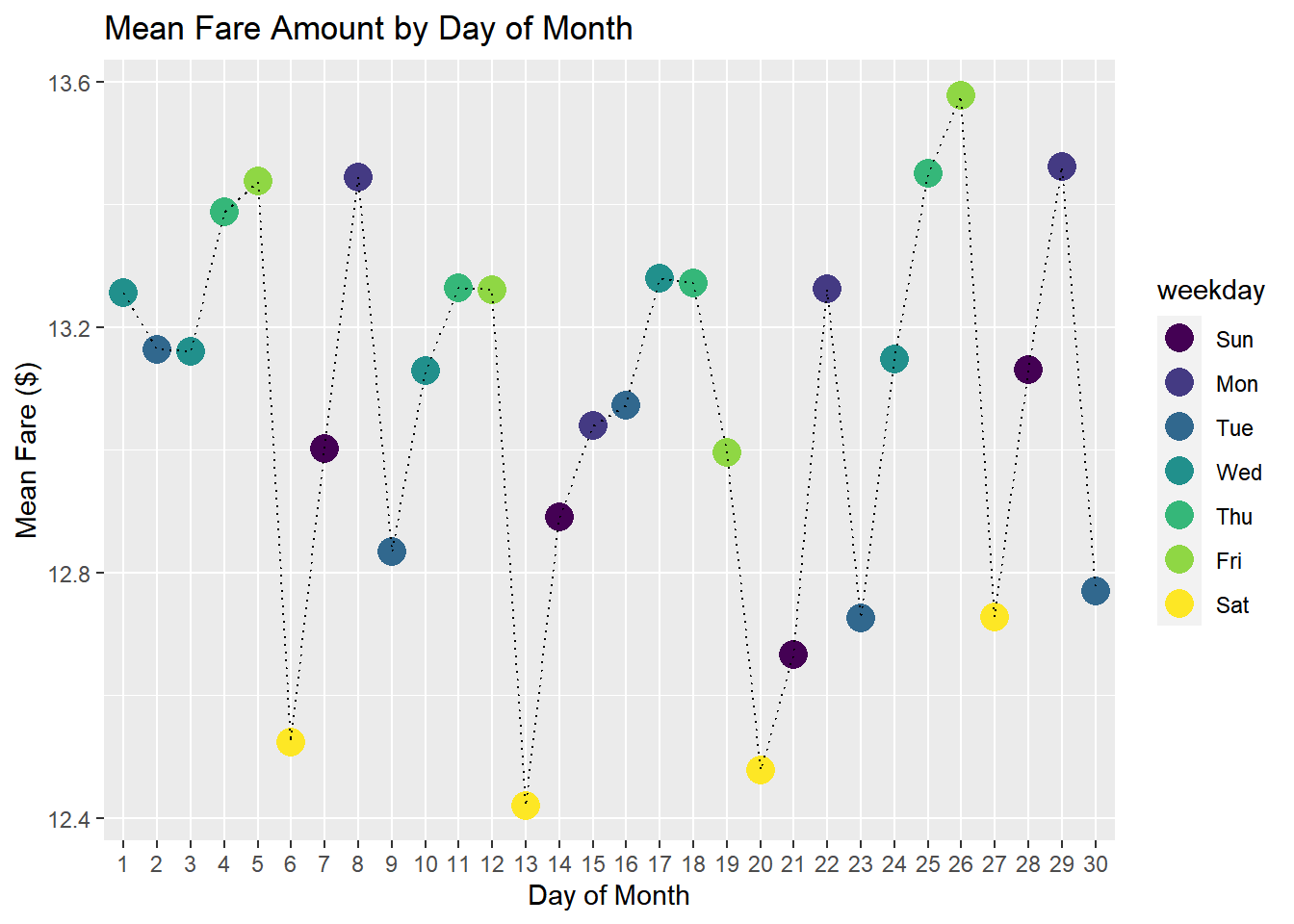
Average fares are smallest on Saturdays and largest on Thursdays and Sundays.
Let’s investigate the relationship between fare amount, hour of day, weekday and payment type:
taxi %>%
filter(fare_amount < 100,payment_type_label %in% c('Credit Card','Cash')) %>%
group_by(weekday,hour.trip.start,payment_type_label) %>%
summarize(mean.fare=mean(fare_amount)) %>%
ggplot(aes(x=hour.trip.start,y=mean.fare,color=payment_type_label,group=payment_type_label)) +
geom_point(size=2) + geom_line() +
facet_wrap(~weekday,nrow=1)+
scale_x_discrete(breaks=c(0,6,12,18))+
labs(y ='Mean Fare ($)',
x = 'Hour of Trip Start',
title = 'Mean Fares by Time of Day and Weekday')`summarise()` has grouped output by 'weekday', 'hour.trip.start'. You can
override using the `.groups` argument.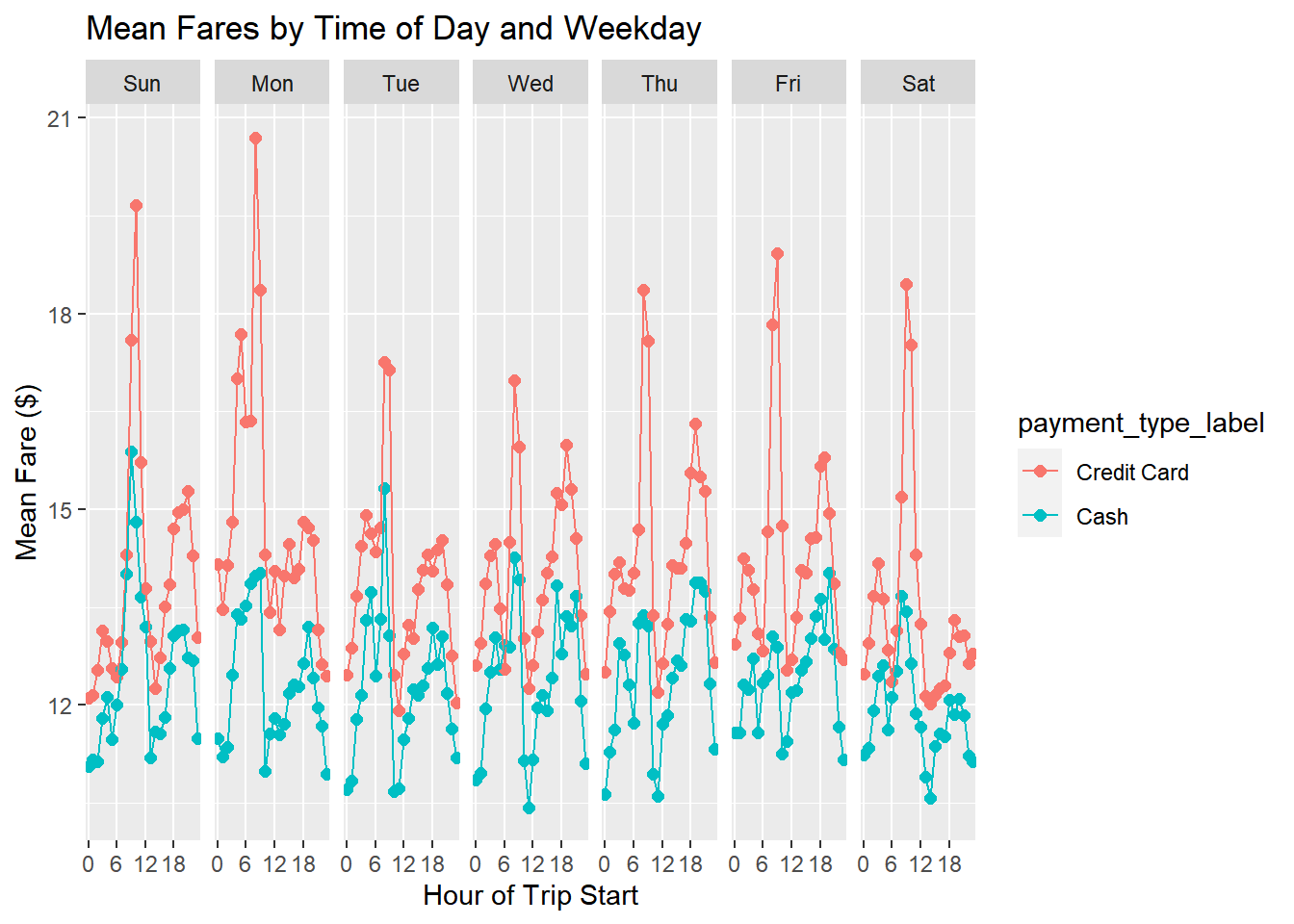
Mean fares tend to be $2-$3 higher for credit card trips.
Taxi Exercise 2: Tips Visualize relationships between tips and payment type and tips and weekday and time of day. The dollar amount of tip is tip_amount
Taxi Exercise 3: Passenger Count Can you find any interesting patterns for passenger count?
Case Study: New York Citibike
In this section we will visualize parts of the citibike data introduced in the Group Summaries section. We start by reading in the data and adding a few transformations:
citibike <- read_rds('data/201508.rds') %>%
mutate(day = factor(mday(as.Date(start.time, "%m/%d/%Y"))),
start.hour=factor(start.hour))How many trips are there for each hour of the day? Let’s check:
ggplot(data=citibike,aes(x=start.hour)) +
geom_bar() +
labs(x = 'Time of Day',
y = 'Number of Trips')+
theme(axis.text.x = element_text(size=8,angle=90))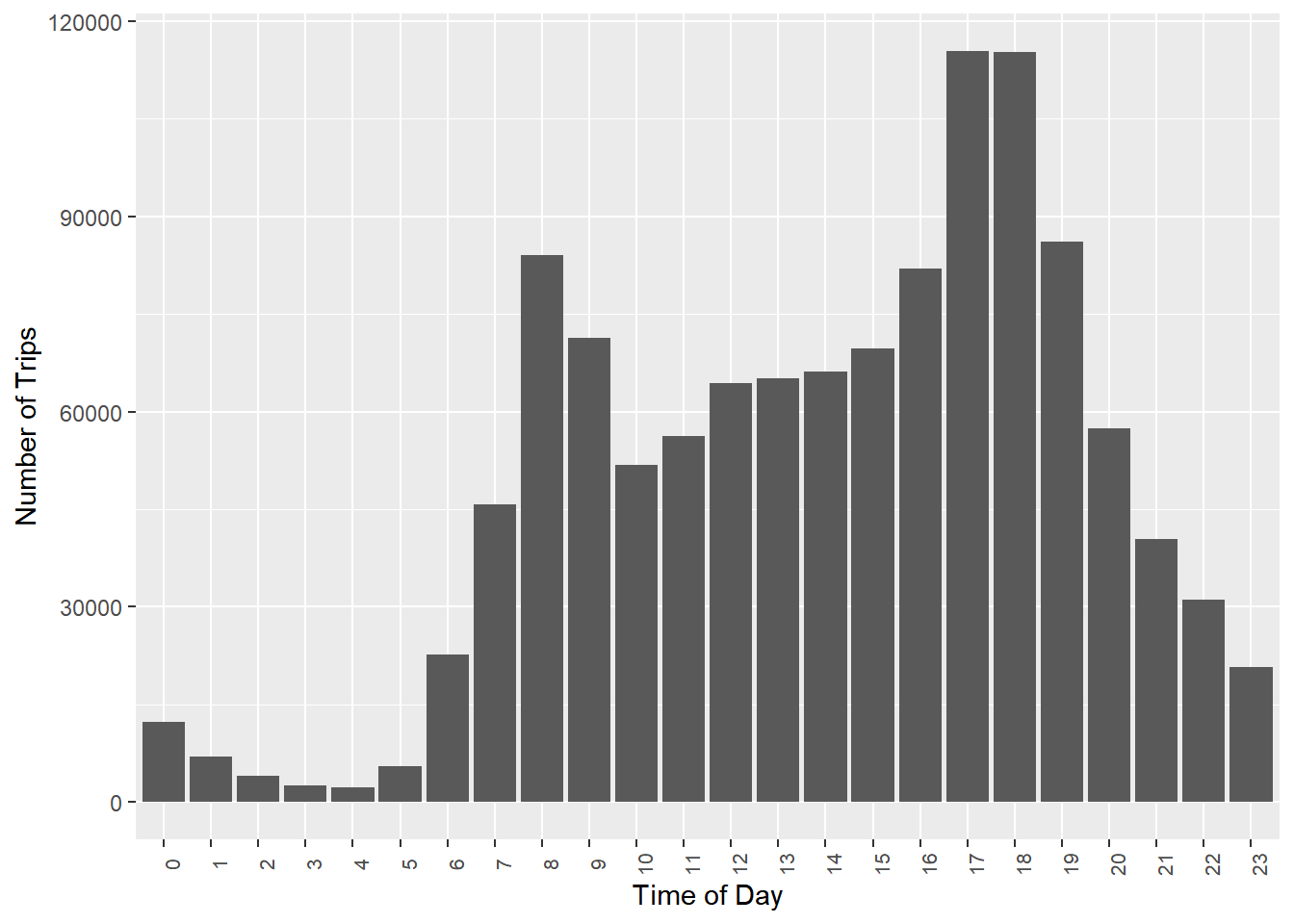
Hmmm…looks like there are large rush hour effects - both morning and afternoon. But it this true for both user segments?
ggplot(data=citibike,aes(x=start.hour)) + geom_bar() +
labs(x = 'Time of Day',
y = 'Number of Trips')+
theme(axis.text.x = element_text(size=8,angle=90)) +
facet_wrap(~usertype)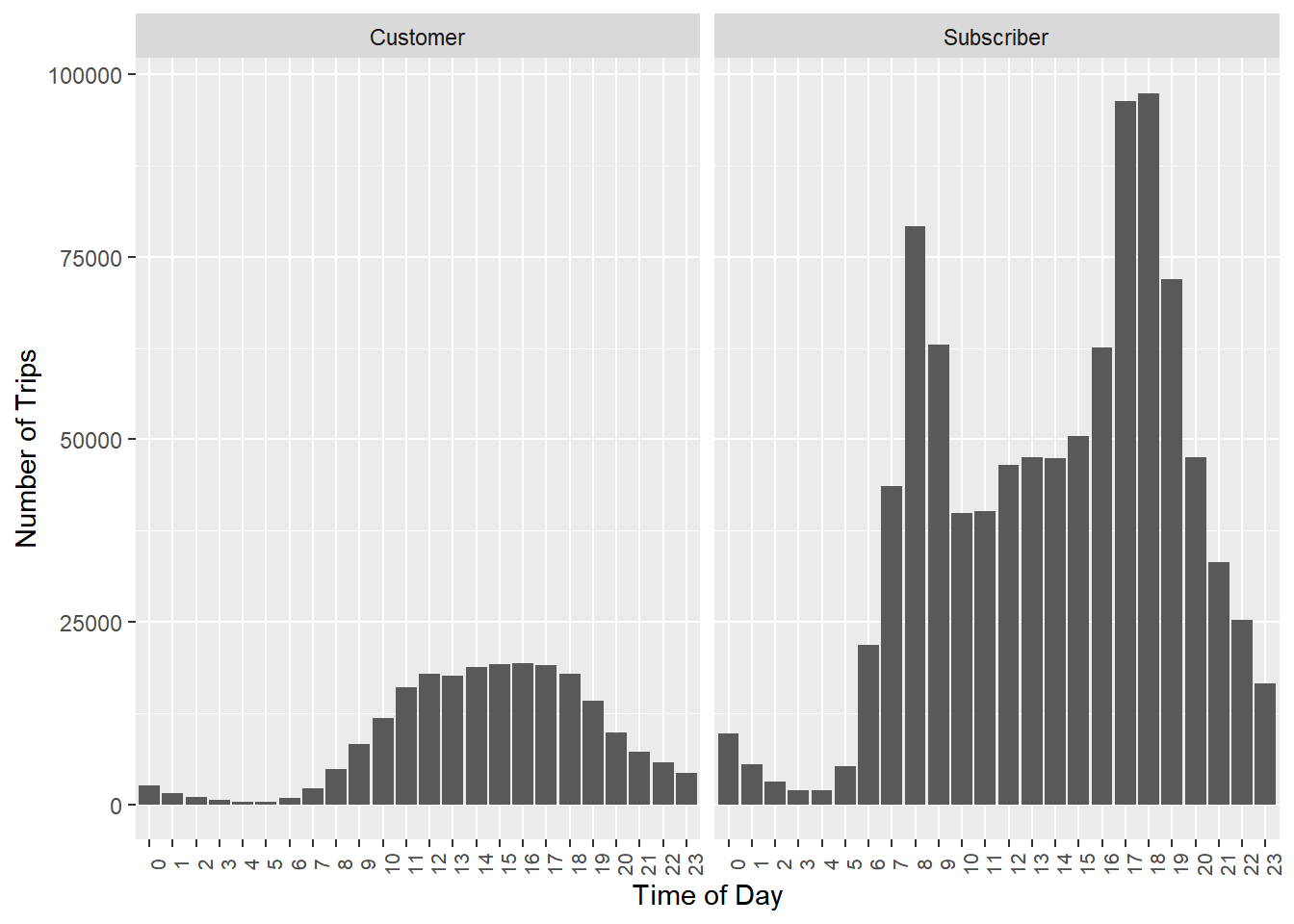
No - rush hour spikes seems to be limited to the “Subscriber” segment.
How about trips by weekday?
ggplot(data=citibike,aes(x=weekday)) + geom_bar() +
labs(x = 'Day of Week',
y = 'Number of Trips',
title = 'Number of Bike Trips by Day of Week') 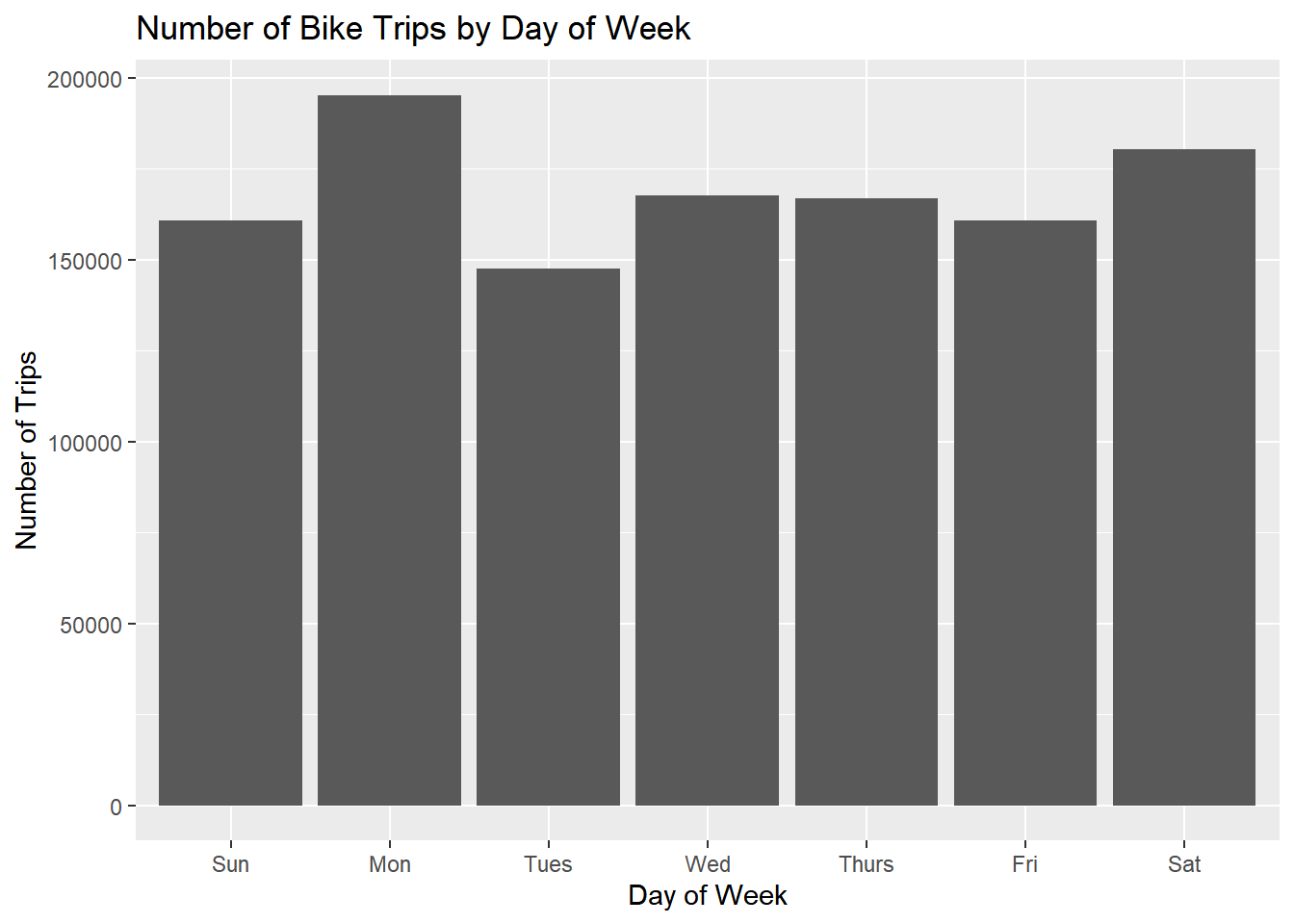
This suffers from the same problem that we encountered for the taxi data - some weekdays occur 5 times in a month while others only occur 4 times. We can correct this the same say as for the taxi data:
citibike %>%
group_by(day) %>%
summarize(n=n(),
weekday = weekday[1]) %>%
group_by(weekday) %>%
summarize(n.m=mean(n)) %>%
ggplot(aes(x=weekday,y=n.m)) + geom_bar(stat='identity') +
labs(x = 'Day of Week',
y = 'Number of Trips',
title = 'Number of Bike Trips by Day of Week') 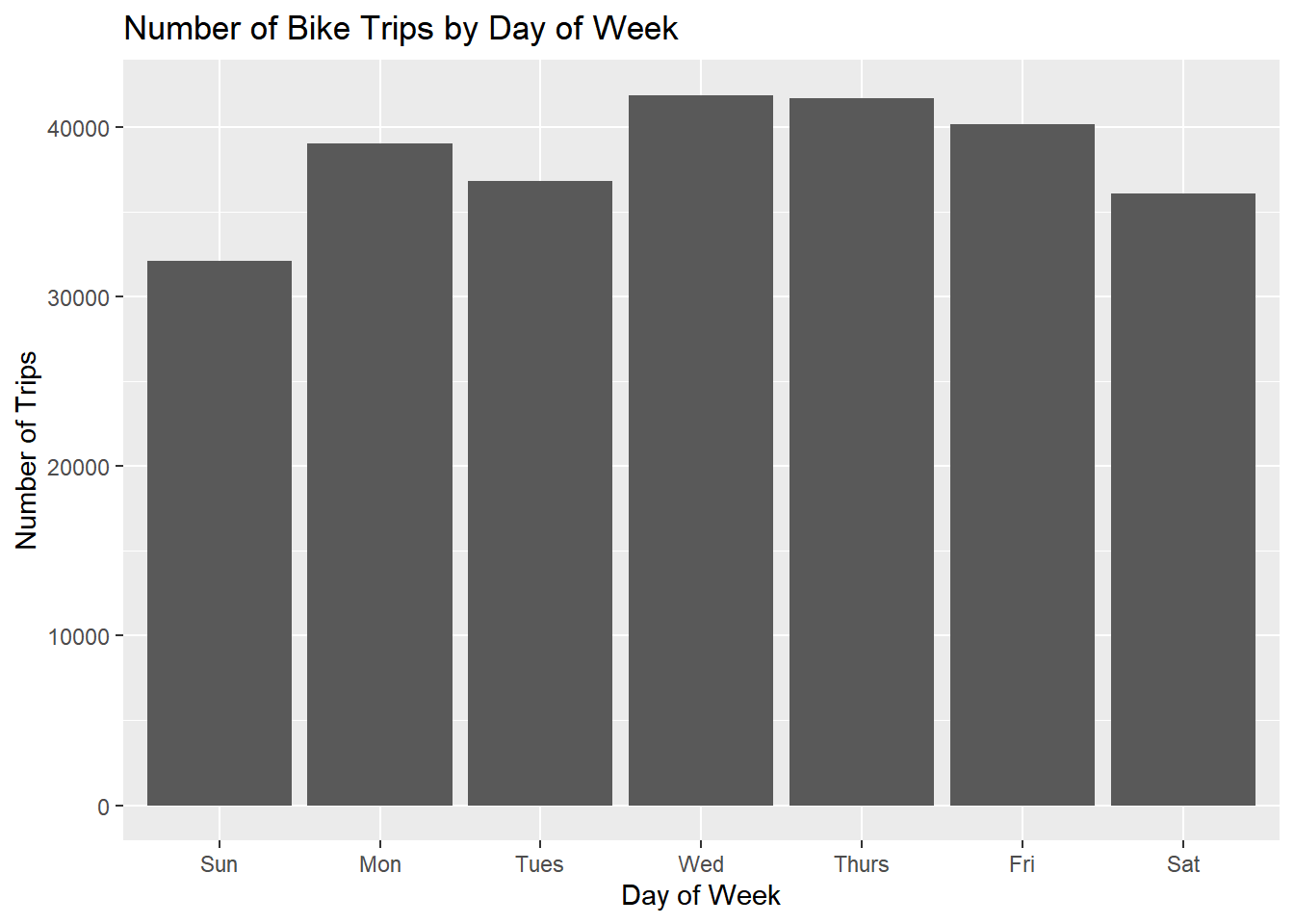
The fewest number of trips occurs on weekends. Is this pattern the same for both segments?
citibike %>%
group_by(day,usertype) %>%
summarize(n=n(),
weekday = weekday[1]) %>%
group_by(weekday,usertype) %>%
summarize(n.m=mean(n)) %>%
ggplot(aes(x=weekday,y=n.m)) + geom_bar(stat='identity') +
labs(x = 'Day of Week',
y = 'Number of Trips',
title = 'Number of Bike Trips by Day of Week') +
facet_wrap(~usertype) `summarise()` has grouped output by 'day'. You can override using the `.groups`
argument.
`summarise()` has grouped output by 'weekday'. You can override using the
`.groups` argument.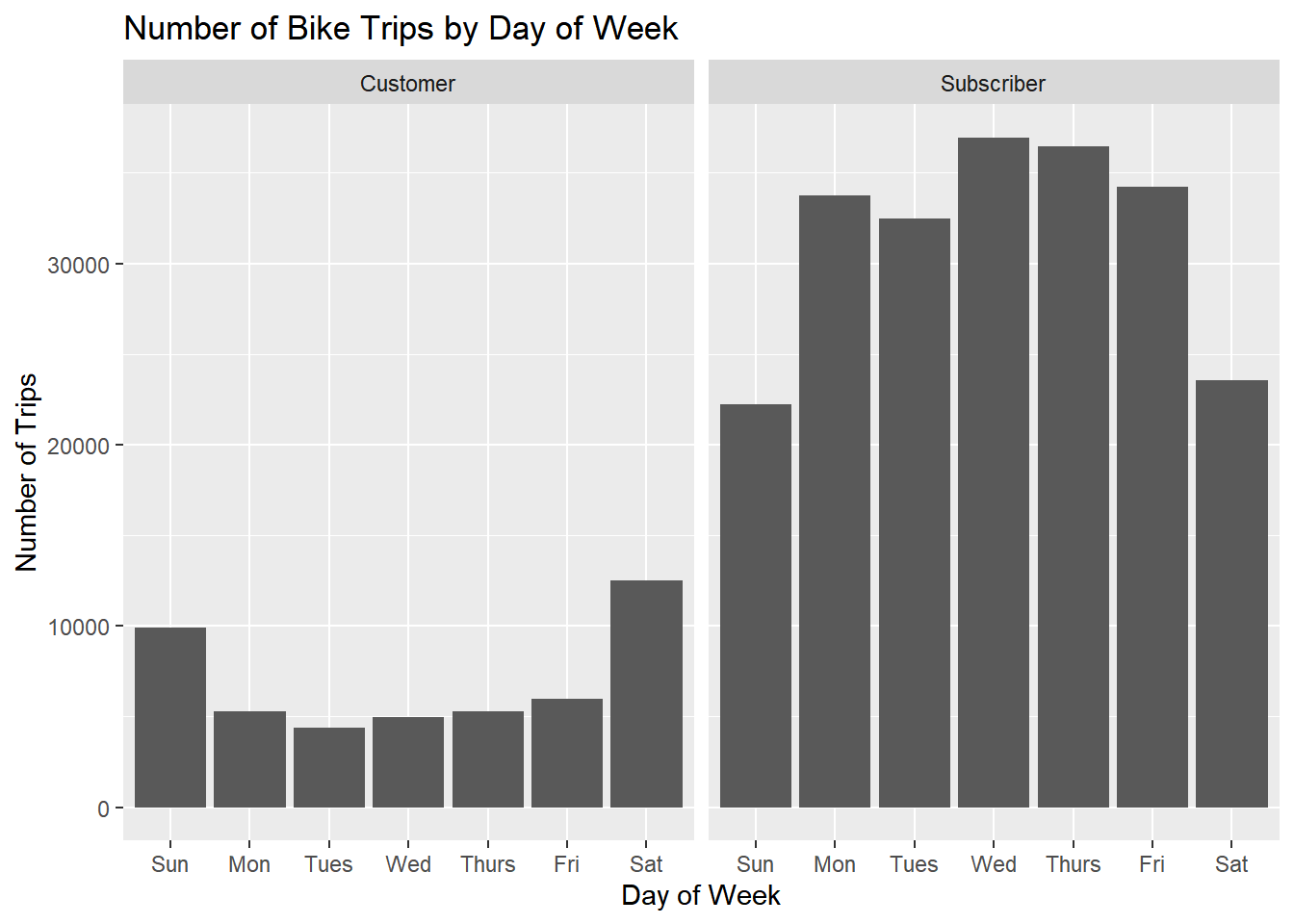
That’s interesting! For “Customers” we see spikes on weekends, while the opposite is true for “Subcribers”. This is consistent with the interpretation of customers as tourists and subscribers as locals.
Let’s put it all together - trips by weekday by segment by time of day:
citibike %>%
group_by(day,usertype,start.hour) %>%
summarize(n=n(),
weekday = weekday[1]) %>%
group_by(weekday,usertype,start.hour) %>%
summarize(n.m=mean(n)) %>%
ggplot(aes(x=start.hour,y=n.m,fill=weekday)) +
geom_bar(stat='identity') +
labs(x = 'Time of Day',
y = 'Number of Trips',
title = 'Number of Bike Trips by Time of Day and Weekday')+
facet_grid(weekday~usertype) +
theme(axis.text.x = element_text(size=8,angle=90),
legend.position="none")`summarise()` has grouped output by 'day', 'usertype'. You can override using
the `.groups` argument.
`summarise()` has grouped output by 'weekday', 'usertype'. You can override
using the `.groups` argument.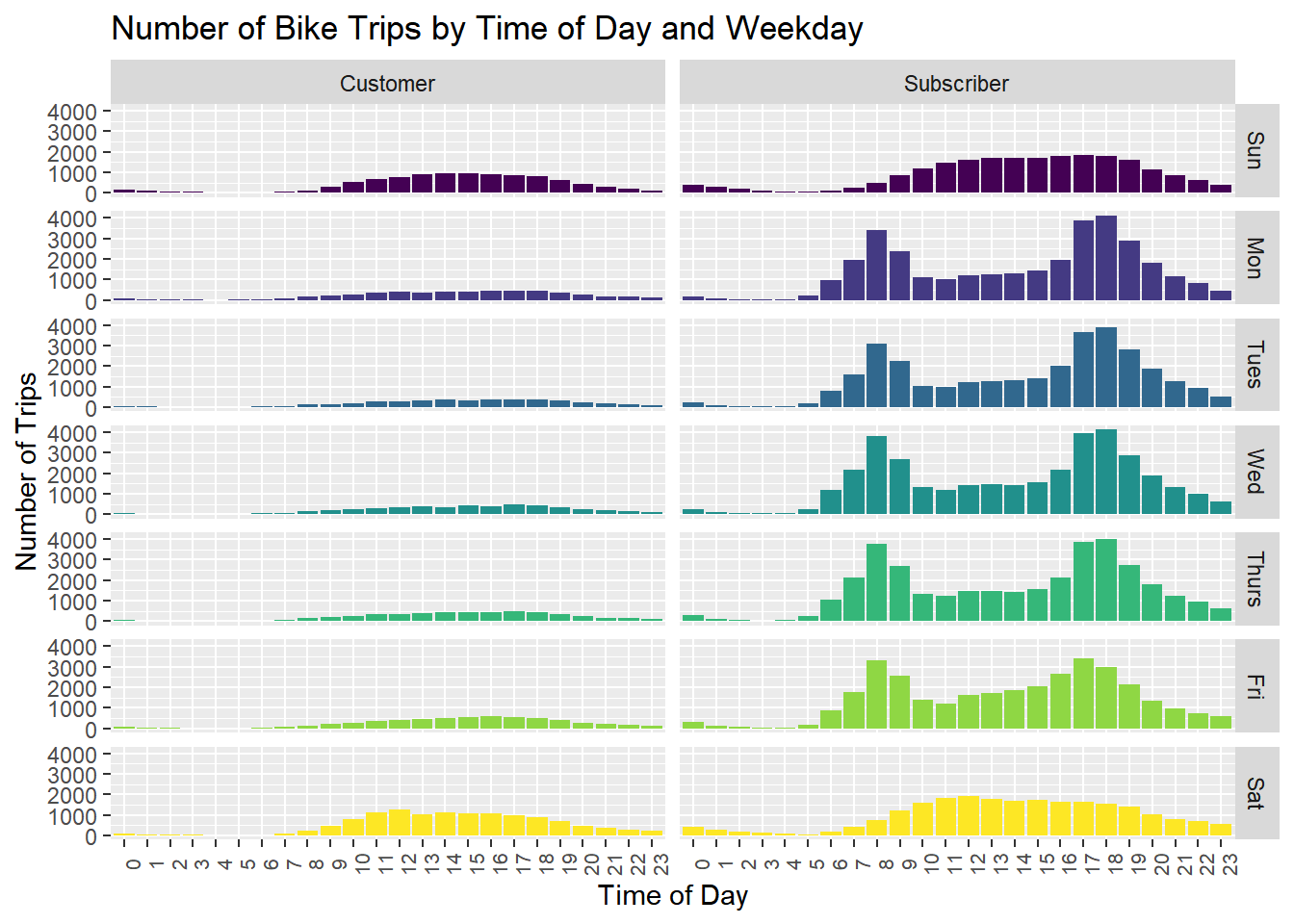
Even more interesting: On weekends, “Subscribers” as as “Customers” - no rush hour spikes.
Now let’s turn to analyzing trip durations rather than the number of trips. What does the distribution of trip durations look like? Remember from above that trip duration is recorded in seconds. This is hard to think about. Let’s start by defining a new variable, which is trip duration in minutes. Also, based on analyzing this data in the Group Summaries section, we ignore the few outlier trips with of extreme length:
citibike <- citibike %>%
mutate(tripduration.m = tripduration/60)
citibike %>%
filter(tripduration.m < 100) %>%
ggplot(aes(x=tripduration.m)) + geom_histogram()+
labs(x = 'Trip Duration (min.))',
y = 'Number of Trips')`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.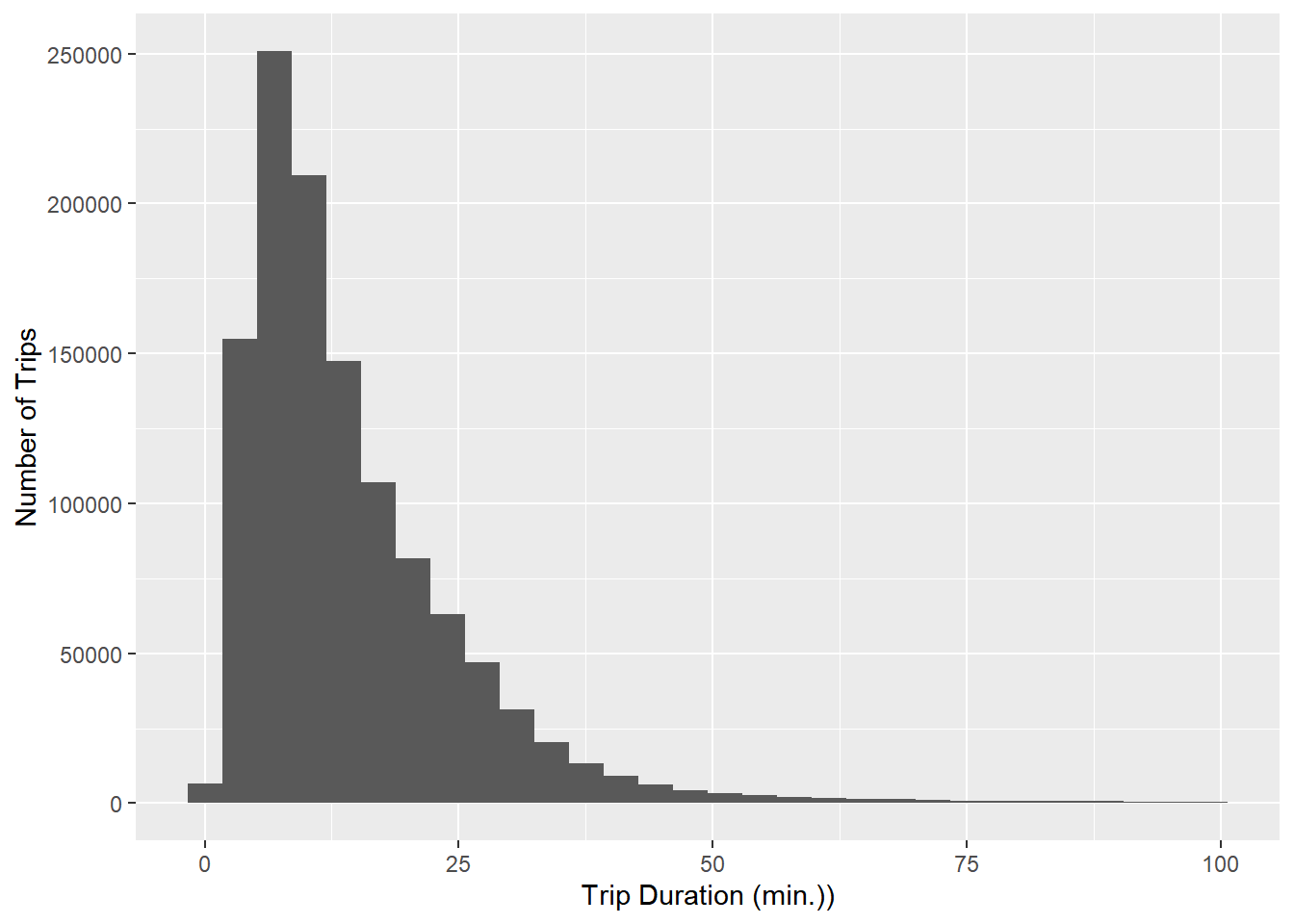
This is a skewed distribution with a long right tail. Most trips are less than 30 minutes. Do the two segments have similar duration distributions?
citibike %>%
filter(tripduration.m < 100) %>%
ggplot(aes(x=tripduration.m)) +
geom_histogram()+
labs(x = 'Trip Duration (min.)',
y = 'Number of Trips') +
facet_wrap(~usertype)`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.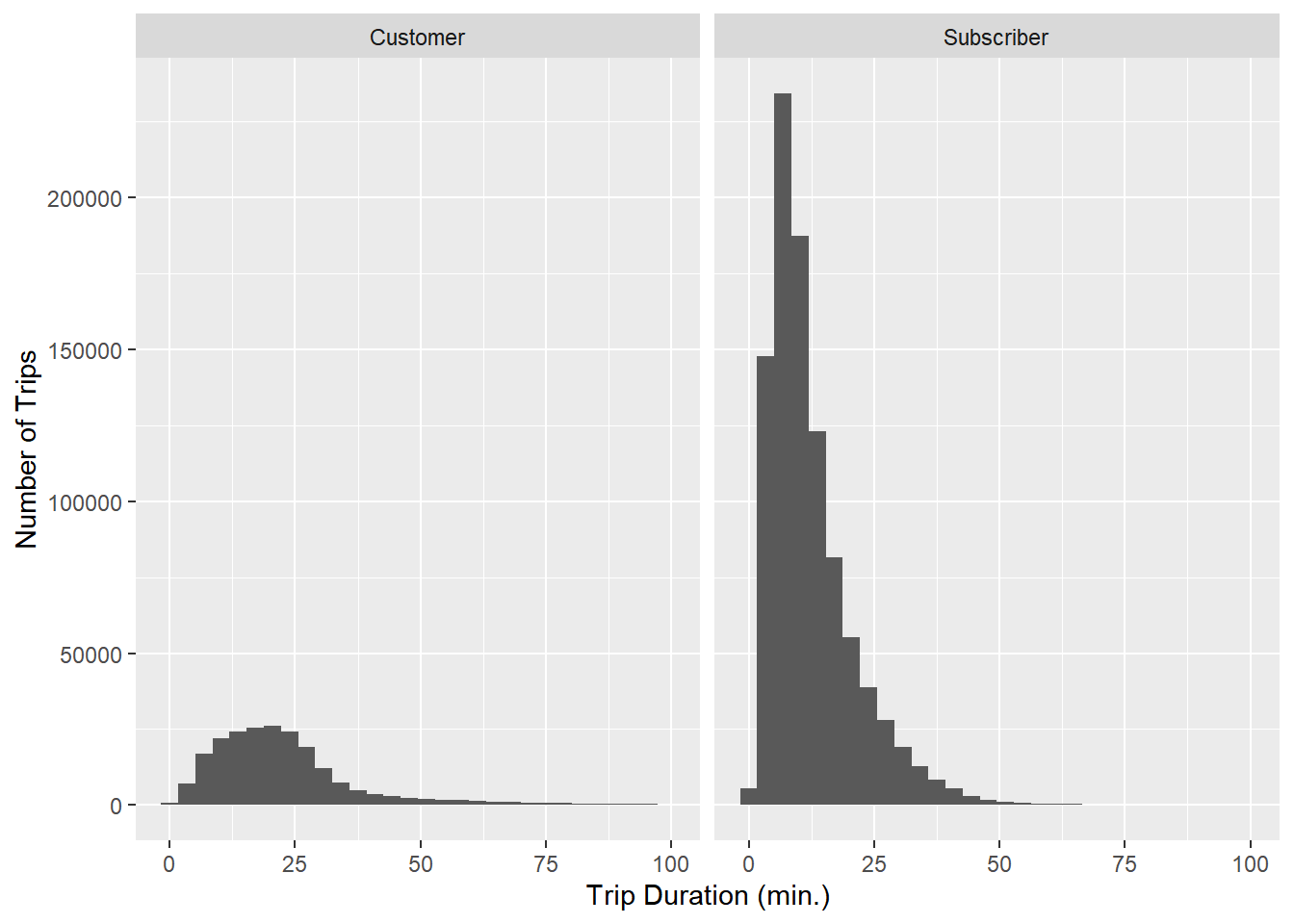
These distributions are different - the “Customer” distribution is much less skewed with more weight on longer trips. This is more evident if we plot the density versions of the histograms (a “density” is just a smoothed version of a histogram):
citibike %>%
filter(tripduration.m < 100) %>%
ggplot(aes(x=tripduration.m,fill=usertype)) +
geom_density(alpha=0.2) +
labs(x = 'Trip Duration (min.)',
y = 'Number of Trips') 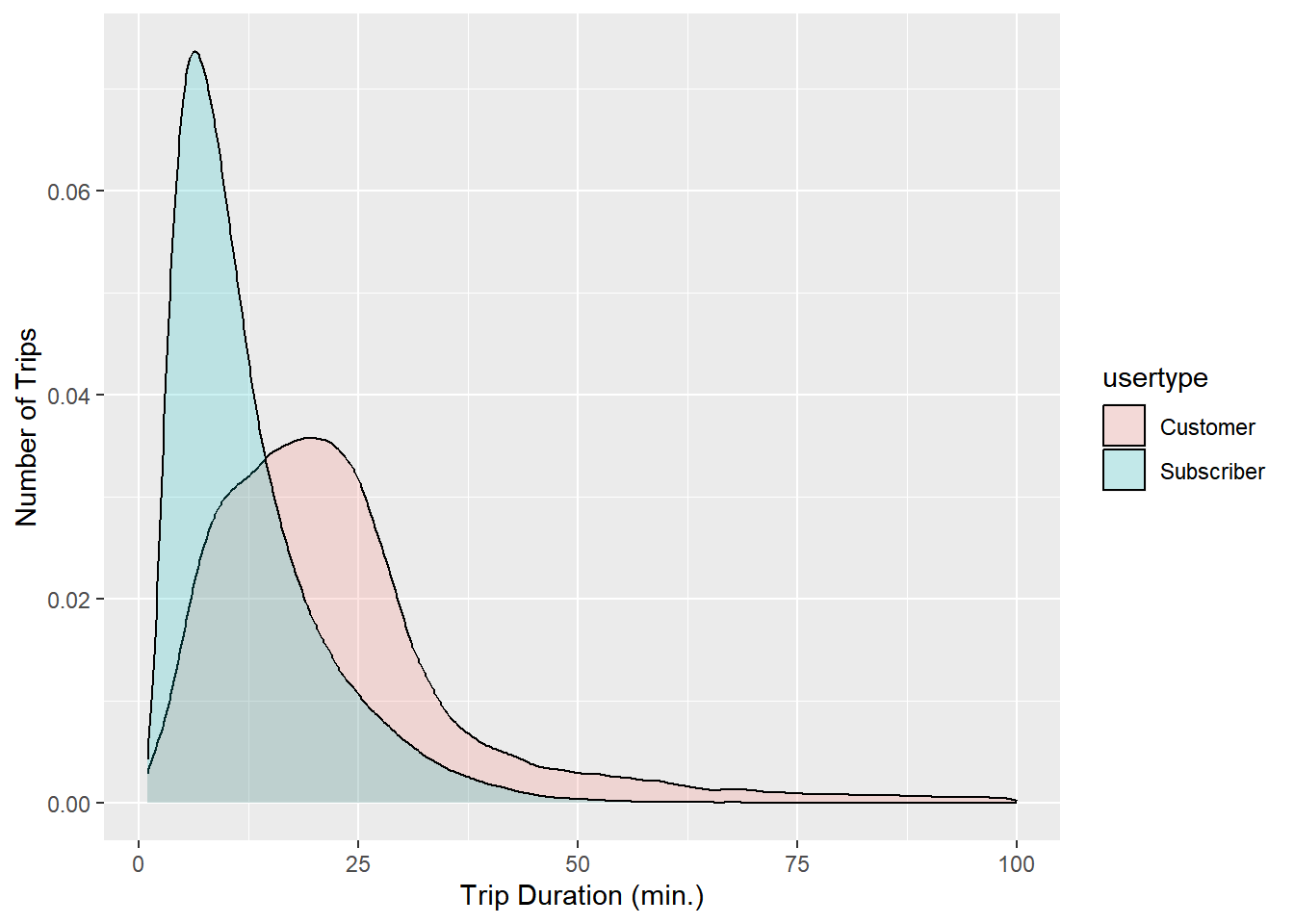
Here we clearly see that customers take longer trips than subscribers.
Finally, let’s look at effect of gender and birth year on trip duration. Do segments defined by gender and age take different trips in terms of duration?
citibike %>%
filter(!birth.year=='NA', gender %in% c('female','male')) %>%
mutate(birth.year.f=cut(as.numeric(birth.year),
breaks = c(0,1955,1965,1975,1985,1990,2000),
labels=c('<1955','1955-1964','1965-1974','1975-1984','1985-1989','>=1990'))) %>%
group_by(birth.year.f,gender) %>%
summarize(med.trip.dur = median(tripduration.m)) %>%
ggplot(aes(x=birth.year.f,y=med.trip.dur,group=gender,color=gender)) +
geom_point() +
geom_line(linetype='dotted') +
labs(y = 'Trip Duration (min.)',
x = 'Age Group',
title = 'Median Trip Duration by Gender and Birth Year')`summarise()` has grouped output by 'birth.year.f'. You can override using the
`.groups` argument.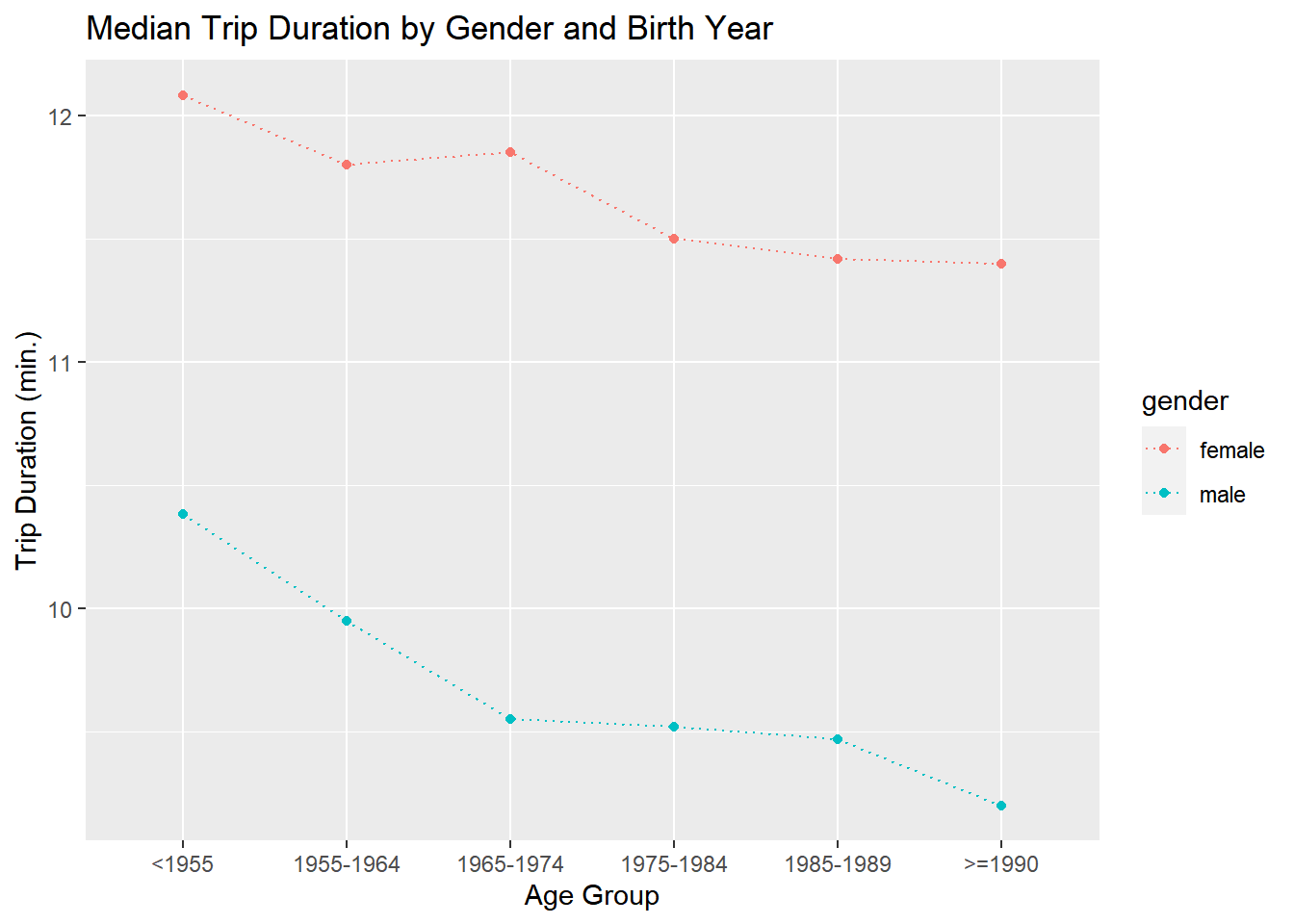
Answer Yes! Men take shorter (in time) trips than women at any age. Furthermore, younger riders of any gender take shorter trips than older riders.